主要介绍(1)搭建UNIX世界框架的三个函数:fork(),wait()以及exec函数族;(2)守护进程;(3)系统日志
注:标题中显示的函数数字表示该函数在man手册中所在章节(第2章的是系统调用函数,第3章的是标准函数)
进程标识符
pid_t:有符号的16位的整型数;现在pid_t在每一个不同机器上占多少位是不确定的。
常用ps指令组合:ps axf,ps axm,ps ax -L。
进程号是顺次向下使用,有别于文件描述符。
GETPID(2)
NAME
getpid, getppid - get process identification
SYNOPSIS
#include <sys/types.h>
#include <unistd.h>
pid_t getpid(void);
pid_t getppid(void);
DESCRIPTION
getpid() returns the process ID of the calling process. (This is often used by routines that generate unique temporary filenames.)
getppid() returns the process ID of the parent of the calling process.
进程的产生
注:很多人学不好进程是什么,就是对fork()函数理解不够透彻。
setjmp()函数执行一次,返回两次。fork()函数也是执行一次,返回两次,返回给两个不同的进程。
为啥有些函数会执行一次,返回两次?如何实现的?
fork(2)
FORK(2)
NAME
fork - create a child process
SYNOPSIS
#include <unistd.h>
pid_t fork(void);
DESCRIPTION
fork() creates a new process by duplicating the calling process. The new process is referred to as the child process. The calling process is referred to as the parent process.
The child process and the parent process run in separate memory spaces. At the time of fork() both memory spaces have the same content. Memory writes, file mappings (mmap(2)), and unmappings (munmap(2)) performed by one of the processes do not affect the other.
The child process is an exact duplicate of the parent process except for the following points:
The child has its own unique process ID, and this PID does not match the ID of any existing process group (setpgid(2)).
The child’s parent process ID is the same as the parent’s process ID.
The child does not inherit its parent’s memory locks (mlock(2), mlockall(2)).
Process resource utilizations (getrusage(2)) and CPU time counters (times(2)) are reset to zero in the child.
The child’s set of pending signals is initially empty (sigpending(2)).
The child does not inherit semaphore adjustments from its parent (semop(2)).
The child does not inherit process-associated record locks from its parent (fcntl(2)). (On the other hand, it does inherit fcntl(2) open file description locks and flock(2) locks from its parent.)
The child does not inherit timers from its parent (setitimer(2), alarm(2), timer_create(2)).
The child does not inherit outstanding asynchronous I/O operations from its parent (aio_read(3), aio_write(3)), nor does it inherit any asynchronous I/O contexts from its parent (see io_setup(2)).
The process attributes in the preceding list are all specified in POSIX.1. The parent and child also differ with respect to the following Linux-specific process attributes:
The child does not inherit directory change notifications (dnotify) from its parent (see the description of F_NOTIFY in fcntl(2)).
The prctl(2) PR_SET_PDEATHSIG setting is reset so that the child does not receive a signal when its parent terminates.
The default timer slack value is set to the parent’s current timer slack value. See the description of PR_SET_TIMERSLACK in prctl(2).
Memory mappings that have been marked with the madvise(2) MADV_DONTFORK flag are not inherited across a fork().
The termination signal of the child is always SIGCHLD (see clone(2)).
The port access permission bits set by ioperm(2) are not inherited by the child; the child must turn on any bits that it requires using ioperm(2).
Note the following further points:
The child process is created with a single thread—the one that called fork(). The entire virtual address space of the parent is replicated in the child, including the states of mutexes, condition variables, and other pthreads objects; the use of pthread_atfork(3) may be helpful for dealing with problems that this can cause.
After a fork(2) in a multithreaded program, the child can safely call only async-signal-safe functions (see signal(7)) until such time as it calls execve(2).
The child inherits copies of the parent’s set of open file descriptors. Each file descriptor in the child refers to the same open file description (see open(2)) as the corresponding file descriptor in the parent. This means that the two descriptors share open file status flags, current file offset, and signal-driven I/O attributes (see the description of F_SETOWN and F_SETSIG in fcntl(2)).
The child inherits copies of the parent’s set of open message queue descriptors (see mq_overview(7)). Each descriptor in the child refers to the same open message queue description as the corresponding descriptor in the parent. This means that the two descriptors share the same flags (mq_flags).
The child inherits copies of the parent’s set of open directory streams (see opendir(3)). POSIX.1 says that the corresponding directory streams in the parent and child may share the directory stream positioning; on Linux/glibc they do not.
RETURN VALUE
On success, the PID of the child process is returned in the parent, and 0 is returned in the child. On failure, -1 is returned in the parent, no child process is created, and errno is set appropriately.
ERRORS
EAGAIN A system-imposed limit on the number of threads was encountered. There are a number of limits that may trigger this error: the RLIMIT_NPROC soft resource limit (set via setrlimit(2)), which limits the number of processes and threads for a real user ID, was reached; the kernel’s system-wide limit on the number of processes and threads, /proc/sys/kernel/threads-max, was reached (see proc(5)); or the maximum number of PIDs, /proc/sys/kernel/pid_max, was reached (see proc(5)).
EAGAIN The caller is operating under the SCHED_DEADLINE scheduling policy and does not have the reset-on-fork flag set. See sched(7).
ENOMEM fork() failed to allocate the necessary kernel structures because memory is tight.
ENOSYS fork() is not supported on this platform (for example, hardware without a Memory-Management Unit).
CONFORMING TO
POSIX.1-2001, POSIX.1-2008, SVr4, 4.3BSD.
NOTES
Under Linux, fork() is implemented using copy-on-write pages, so the only penalty that it incurs is the time and memory required to duplicate the parent’s page tables, and to create a unique task structure for the child.
C library/kernel differences
Since version 2.3.3, rather than invoking the kernel’s fork() system call, the glibc fork() wrapper that is provided as part of the NPTL threading implementation invokes clone(2) with flags that provide the same effect as the traditional system call. (A call to fork() is equivalent to a call to clone(2) specifying flags as just SIGCHLD.) The glibc wrapper invokes any fork handlers that have been established using pthread_atfork(3).
EXAMPLE
See pipe(2) and wait(2).
SEE ALSO
clone(2), execve(2), exit(2), setrlimit(2), unshare(2), vfork(2), wait(2), daemon(3), capabilities(7), credentials(7)
注意理解关键字:duplicating,意味着拷贝,克隆,一模一样等含义。
fork后父子进程的区别:fork的返回值不一样,pid不同,ppid也不同,未决信号和文件锁不继承,资源利用量归零。
未决信号:还没来得及响应的信号;
资源利用量归零:父进程如果使用了大量资源,怎么能带给子进程呢,否者磁盘限额就没意义了;
举个栗子:
写个程序来演示父子进程间的区别,能通过ps指令来显示父子进程的关系,并且展示缓冲机制在其中起的作用。
1 | // fork.c |
编译运行结果如下:
1 | $ make fork |
永远不要凭空猜测父子进程谁先被调度,因为哪个进程先运行是由调度器的调度策略来决定的。
如果将fork程序运行结果重定向至指定文件中,输出结果如下:
1 | [33994]:Begin! |
“Begin!”字符串打印了两次。如果将printf("[%d]:Begin!\n",getpid());语句中的\n去掉,“Begin!”字符串依旧打印两次。
1 | $ ./fork |
在调用fork()之前,要刷新所有成功打开的流。
全缓冲模式中,\n不表示刷新缓冲区,只表示换行。把Begin语句放到缓冲区中,还没来得及写到文件里去时,直接就fork(),父子进程的缓冲区里各自有一句Begin,那句Begin已经固定了,所以输出的是父进程的进程号。
调用fork()之前,先用fflush()刷新所有成功打开的流,重新编译运行结果如下:
1 | $ make fork |
注:缓冲区机制会造成这样或那样的问题,为什么还要引入这样的机制呢?
vfork(2)
NAME
vfork - create a child process and block parent
SYNOPSIS
#include <sys/types.h>
#include <unistd.h>
pid_t vfork(void);
DESCRIPTION
Standard Description
(From POSIX.1) The vfork() function has the same effect as fork(2), except that the behavior is undefined if the process created by vfork() either modifies any data other than a variable of type pid_t used to store the return value from vfork(), or returns from the function in which vfork() was called, or calls any other function before successfully calling _exit(2) or one of the exec(3) family of functions.
Linux Description
vfork(), just like fork(2), creates a child process of the calling process. For details and return value and errors, see fork(2).
vfork() is a special case of clone(2). It is used to create new processes without copying the page tables of the parent process. It may be useful in performance-sensitive applications where a child is created which then immediately issues an execve(2).
vfork() differs from fork(2) in that the calling thread is suspended until the child terminates (either normally, by calling _exit(2), or abnormally, after delivery of a fatal signal), or it makes a call to execve(2). Until that point, the child shares all memory with its parent, including the stack. The child must not return from the current function or call exit(3), but may call _exit(2).
As with fork(2), the child process created by vfork() inherits copies of various of the caller’s process attributes (e.g., file descriptors, signal dispositions, and current working directory); the vfork() call differs only in the treatment of the virtual address space, as described above.
Signals sent to the parent arrive after the child releases the parent’s memory (i.e., after the child terminates or calls execve(2)).
Historic Description
Under Linux, fork(2) is implemented using copy-on-write pages, so the only penalty incurred by fork(2) is the time and memory required to duplicate the parent’s page tables, and to create a unique task structure for the child. However, in the bad old days a fork(2) would require making a complete copy of the caller’s data space, often needlessly, since usually immediately afterward an exec(3) is done. Thus, for greater efficiency, BSD introduced the vfork() system call, which did not fully copy the address space of the parent process, but borrowed the parent’s memory and thread of control until a call to execve(2) or an exit occurred. The parent process was suspended while the child was using its resources. The use of vfork() was tricky: for example, not modifying data in the parent process depended on knowing which variables were held in a register.
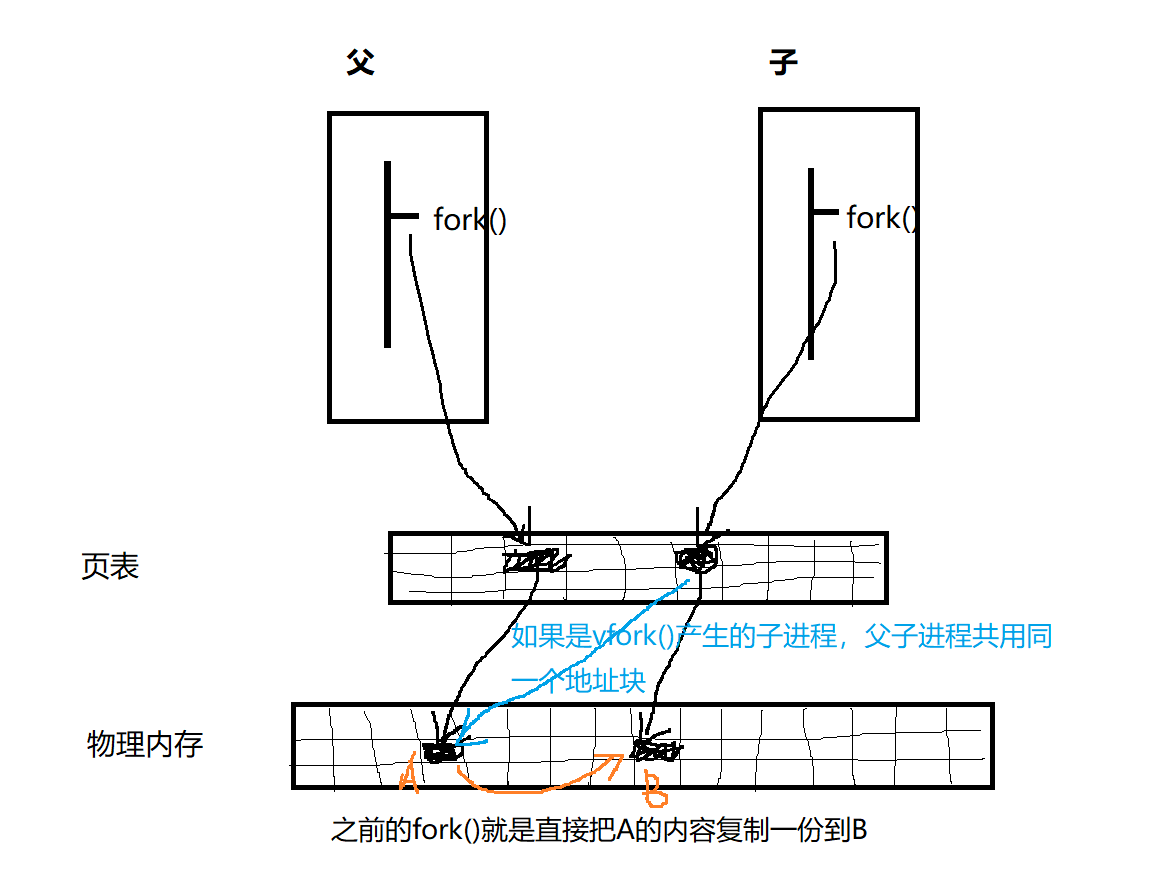
现在的fork()已经不是像上图那样了,而是添加了一个写时拷贝技术。在fork()时,父子进程共用同一个数据模块,如果父子进程对这些数据块是只读不写的,那谁也不会变,如果父子进程中有谁企图通过指针去写,那谁就自己memory copy一份,改自己的。

举个栗子:如果父子两个进程对于A都是只读,那谁也不干涉谁;如果有谁要改变A里面的数据,比如父进程,那么父进程memory copy一份到B,指针指向B了,改B里面的数据,A里面的数据不变。父子进程谁要改数据那就谁去拷贝。
fork()后来加了写时拷贝技术,相当于把vfork()融合进来了,甚至比它更灵活些,现在vfork()都快要废弃了。
面试题:在父进程中成功打开一个文件,捏着一个文件描述符fd,vfork()之后,在子进程中执行close(fd),请问父进程中的fd有没有关闭?
(From POSIX.1) The vfork() function has the same effect as fork(2), except that the behavior is undefined if the process created by vfork() either modifies any data other than a variable of type pid_t used to store the return value from vfork(), or returns from the function in which vfork() was called, or calls any other function before successfully calling _exit(2) or one of the exec(3) family of functions.
用vfork()产生的子进程只能做这两件事,所以父进程中的fd有没有关闭是不清楚的。
进程的消亡
wait(2)
wait()收尸是死等,一直等到有进程的状态发生改变,会有信号通知wait(),然后wait()才去收尸。如果子进程出了问题,永远没办法回来或者不能通知wait()去给它收尸,那wait()就会一直等着。
NAME
wait, waitpid - wait for process to change state
SYNOPSIS
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *status);
pid_t waitpid(pid_t pid, int *status, int options);
DESCRIPTION
All of these system calls are used to wait for state changes in a child of the calling process, and obtain information about the child whose state has changed. A state change is considered to be: the child terminated; the child was stopped by a signal; or the child was resumed by a signal. In the case of a terminated child, performing a wait allows the system to release the resources associated with the child; if a wait is not performed, then the terminated child remains in a “zombie” state (see NOTES below).
If a child has already changed state, then these calls return immediately. Otherwise, they block until either a child changes state or a signal handler interrupts the call (assuming that system calls are not automatically restarted using the SA_RESTART flag of sigaction(2)). In the remainder of this page, a child whose state has changed and which has not yet been waited upon by one of these system calls is termed waitable.
wait() and waitpid()
The wait() system call suspends execution of the calling process until one of its children terminates. The call wait(&status) is equivalent to: waitpid(-1, &status, 0);
The waitpid() system call suspends execution of the calling process until a child specified by pid argument has changed state. By default, waitpid() waits only for terminated children, but this behavior is modifiable via the options argument, as described below.
The value of pid can be:
< -1 meaning wait for any child process whose process group ID is equal to the absolute value of pid.
-1 meaning wait for any child process.
0 meaning wait for any child process whose process group ID is equal to that of the calling process.
> 0 meaning wait for the child whose process ID is equal to the value of pid.
The value of options is an OR of zero or more of the following constants:
WNOHANG return immediately if no child has exited.
WUNTRACED also return if a child has stopped (but not traced via ptrace(2)). Status for traced children which have stopped is provided even if this option is not specified.
WCONTINUED (since Linux 2.6.10) also return if a stopped child has been resumed by delivery of SIGCONT.
(For Linux-only options, see below.)
If status is not NULL, wait() and waitpid() store status information in the int to which it points. This integer can be inspected with the following macros (which take the integer itself as an argument, not a pointer to it, as is done in wait() and waitpid()!):
WIFEXITED(status) returns true if the child terminated normally, that is, by calling exit(3) or _exit(2), or by returning from main().
WEXITSTATUS(status) returns the exit status of the child. This consists of the least significant 8 bits of the status argument that the child specified in a call to exit(3) or _exit(2) or as the argument for a return statement in main(). This macro should be employed only if WIFEXITED returned true.
WIFSIGNALED(status) returns true if the child process was terminated by a signal.
WTERMSIG(status) returns the number of the signal that caused the child process to terminate. This macro should be employed only if WIFSIGNALED returned true.
WCOREDUMP(status) returns true if the child produced a core dump. This macro should be employed only if WIFSIGNALED returned true. This macro is not specified in POSIX.1-2001 and is not available on some UNIX implementations (e.g., AIX, SunOS). Only use this enclosed in #ifdef WCOREDUMP … #endif.
WIFSTOPPED(status) returns true if the child process was stopped by delivery of a signal; this is possible only if the call was done using WUNTRACED or when the child is being traced (see ptrace(2)).
WSTOPSIG(status) returns the number of the signal which caused the child to stop. This macro should be employed only if WIFSTOPPED returned true.
WIFCONTINUED(status) (since Linux 2.6.10) returns true if the child process was resumed by delivery of SIGCONT.
RETURN VALUE
wait(): on success, returns the process ID of the terminated child; on error, -1 is returned.
waitpid(): on success, returns the process ID of the child whose state has changed; if WNOHANG was specified and one or more child(ren) specified by pid exist, but have not yet changed state, then 0 is returned. On error, -1 is returned.
Each of these calls sets errno to an appropriate value in the case of an error.
waitpid()好用的地方不在于参数pid,而是参数options。options是个位图,最好用的一个是WNOHANG,
WNOHANG return immediately if no child has exited.
即使当前没有任何的child退出,如果加了WNOHANG选项的话,也会立马退出,相当于把waitpid()这个操作由阻塞变成了非阻塞。wait()是阻塞的,但是waitpid()加了WNOHANG选项后可以是非阻塞的。
wait()死等,收一个回来后才能看到是谁,waitpid()可以指定收谁,如果没添加WNOHANG选项,就相当于定向收尸的wait(),死等来收指定pid的子进程,如果添加WNOHANG选项,但子进程还在正常运行或者没达到收尸条件,马上走人,只有子进程结束了,那就收回来。收尸是等进程状态发生变化,才能取出退出码,释放资源,如果一个进程正常运行,收尸是收不回来的。
分组的目的就是统一操作,方便管理。
举个栗子:
写个程序来输出指定范围内的质数,将计算任务分配给子进程来完成,父进程负责收尸。
1 | // primer.c |
某次运行结果如下:
1 | $ ./primer |
exec函数族
“few”:fork,exec,wait。
父进程创建子进程的时候,是通过复制自己来实现的。
理解exec函数族的核心目的:它们用于在当前进程上下文中执行一个新程序。它们都会替换当前进程的映像,但保留进程ID、打开的文件描述符等。
区分函数:尝试将不同的exec函数与其特定功能关联起来:
- execl 和 execv:这两个函数允许你传递一个参数列表,其中execl使用可变参数列表,execv使用参数数组。
- execle 和 execve:这两个函数除了接受参数列表外,还允许你传递环境变量数组。其中execle使用可变参数列表,execve使用参数数组。
- execlp 和 execvp:这两个函数会在PATH环境变量中搜索可执行文件,而不需要提供可执行文件的完整路径。其中execlp使用可变参数列表,execvp使用参数数组。
execve(2)
EXECVE(2)
NAME
execve - execute program
SYNOPSIS
#include <unistd.h>
int execve(const char *filename, char *const argv[], char *const envp[]);
DESCRIPTION
execve() executes the program pointed to by filename. filename must be either a binary executable, or a script starting with a line of the form:
#! interpreter [optional-arg]
For details of the latter case, see “Interpreter scripts” below.
argv is an array of argument strings passed to the new program. By convention, the first of these strings should contain the filename associated with the file being executed. envp is an array of strings, conventionally of the form key=value, which are passed as environment to the new program. Both argv and envp must be terminated by a null pointer. The argument vector and environment can be accessed by the called program’s main function, when it is defined as:
int main(int argc, char *argv[], char *envp[])
execve() does not return on success, and the text, data, bss, and stack of the calling process are overwritten by that of the program loaded.
RETURN VALUE
On success, execve() does not return, on error -1 is returned, and errno is set appropriately.
Historical
With UNIX V6, the argument list of an exec() call was ended by 0, while the argument list of main was ended by -1. Thus, this argument list was not directly usable in a further exec() call. Since UNIX V7, both are NULL.
注:在《The C Programming Language》中,argv在索引中显示为参数向量,而非参数值。
argc:argument count
argv:argument vector
envp:environment pointer
1 | // myecho.c |
1 | // execve.c |
编译运行结果如下:
1 | $ make myecho |
exec(3)
EXEC(3)
NAME
execl, execlp, execle, execv, execvp - execute a file
SYNOPSIS
#include <unistd.h>
extern char **environ;
int execl(const char *path, const char *arg, … /* (char *) NULL */);
int execlp(const char *file, const char *arg, … /* (char *) NULL */);
int execle(const char *path, const char *arg, … /*, (char *) NULL, char * const envp[] */);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
DESCRIPTION
The exec() family of functions replaces the current process image with a new process image. The functions described in this manual page are front-ends for execve(2). (See the manual page for execve(2) for further details about the replacement of the current process image.)
The initial argument for these functions is the name of a file that is to be executed.
The const char *arg and subsequent ellipses in the execl(), execlp(), and execle() functions can be thought of as arg0, arg1, …, argn. Together they describe a list of one or more pointers to null-terminated strings that represent the argument list available to the executed program. The first argument, by convention, should point to the filename associated with the file being executed. The list of arguments must be terminated by a null pointer, and, since these are variadic functions, this pointer must be cast (char *) NULL.
The execv(), execvp(), and execvpe() functions provide an array of pointers to null-terminated strings that represent the argument list available to the new program. The first argument, by convention, should point to the filename associated with the file being executed. The array of pointers must be terminated by a null pointer.
The execle() and execvpe() functions allow the caller to specify the environment of the executed program via the argument envp. The envp argument is an array of pointers to null-terminated strings and must be terminated by a null pointer. The other functions take the environment for the new process image from the external variable environ in the calling process.
RETURN VALUE
The exec() functions return only if an error has occurred. The return value is -1, and errno is set to indicate the error.
ERRORS
All of these functions may fail and set errno for any of the errors specified for execve(2).
NOTES
On some other systems, the default path (used when the environment does not contain the variable PATH) has the current working directory listed after /bin and /usr/bin, as an anti-Trojan-horse measure. Linux uses here the traditional “current directory first” default path.
The behavior of execlp() and execvp() when errors occur while attempting to execute the file is historic practice, but has not traditionally been documented and is not specified by the POSIX standard. BSD (and possibly other systems) do an automatic sleep and retry if ETXTBSY is encountered. Linux treats it as a hard error and returns immediately.
Traditionally, the functions execlp() and execvp() ignored all errors except for the ones described above and ENOMEM and E2BIG, upon which they returned. They now return if any error other than the ones described above occurs.

注:5个exec族函数中,哪些是定长参数,哪些是可变长参数?
进程空间搭建的过程中,在exec阶段就已经有了代码段,已初始化数据段,未初始化数据段等,堆和栈是在后来才搭建起来的。
注:在调用execl()函数之前要刷新所有该刷新的数据流。
1 | // execl.c |
execl()的第二个参数传参一定要从argv[0]开始。
UNIX世界就是由这三个函数搭建起来的:fork(),exec(),wait()。
1 | // few.c |
编译运行结果如下:
1 | $ make few |
1 | // sleep.c |
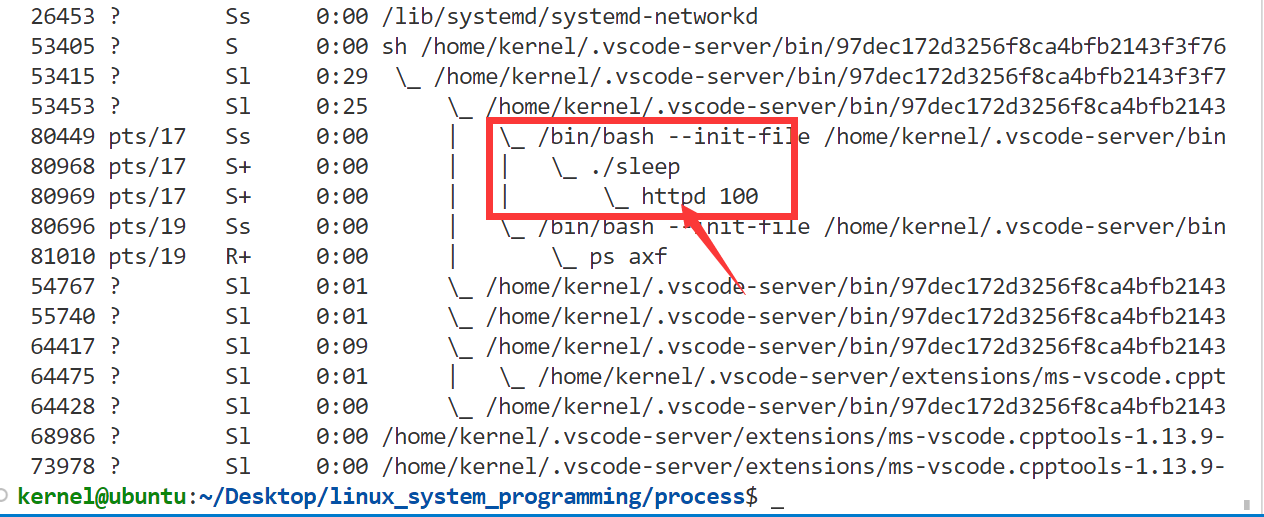
注:argv[0]处的”httpd”类似于一个别名,会显示在进程关系中。这样可以实现木马的一种低级藏身办法,高级一点的可以隐藏在内核模块中,但是这样危害就不如在用户态大了(为啥呀???)。
举个栗子:shell的外部命令实现
shell的外部命令处理思路【伪代码】:
1 |
|
1 | // mysh.c |
GLOB_NOCHECK If no pattern matches, return the original pattern. By default, glob() returns GLOB_NOMATCH if there are no matches.
守护进程
在UNIX系统编程中,经常需要创建守护进程。守护进程一般脱离控制终端,是后台运行的进程,与终端无关。为了使进程完全脱离其父进程和终端,我们需要使用 setsid() 函数来创建新的会话。
注:守护进程一般脱离控制终端,是一个会话的leader,进程组的leader。
setsid(3POSIX)
NAME
setsid — create session and set process group ID
SYNOPSIS
#include <unistd.h>
pid_t setsid(void);
DESCRIPTION
The setsid() function shall create a new session, if the calling process is not a process group leader. Upon return the calling process shall be the session leader of this new session, shall be the process group leader of a new process group, and shall have no controlling terminal. The process group ID of the calling process shall be set equal to the process ID of the calling process. The calling process shall be the only process in the new process group and the only process in the new session.
RETURN VALUE
Upon successful completion, setsid() shall return the value of the new process group ID of the calling process. Otherwise, it shall return −1 and set errno to indicate the error.
ERRORS
The setsid() function shall fail if:
EPERM The calling process is already a process group leader, or the process group ID of a process other than the calling process matches the process ID of the calling process.
setsid() 函数用于创建新的会话,并做以下三件事情:
- 使调用进程成为新会话的领头进程。
- 使调用进程成为新进程组的领头进程。
- 使调用进程没有控制终端。
注意事项:
- 如果调用进程已经是进程组的领头进程,则 setsid() 调用将失败。
- 为了确保调用进程不是进程组的领头进程,通常首先进行 fork() 操作,然后在子进程中调用 setsid()。这样,父进程可以正常退出,而子进程保证不是进程组的领头进程。
- setsid() 使得进程脱离原有的终端、会话和进程组,并建立一个新会话,此时该进程是新会话的领头进程和新进程组的领头进程。
编写原则
- 创建孤儿进程:创建(fork)一个子进程并使父进程退出(exit),使子进程成为孤儿进程。子进程虽然继承了父进程的进程组ID,但获得了一个新的进程ID,这就保证了子进程不是一个进程组的组长进程。这是后面调用 setsid() 的先决条件。
- 创建新的会话:调用 setsid() 创建一个新的会话,使调用进程成为新会话的首进程,一个新进程组的组长进程,没有控制终端。
- 更改工作目录:将守护进程的工作目录更改为根目录(”/“),以确保守护进程不会占用其他文件系统的资源。从父进程处继承过来的当前工作目录可能在一个挂载的文件系统中。因为守护进程通常在系统再引导之前是一直存在的,所以如果守护进程的当前工作目录在一个挂载文件系统中,那么该文件系统就不能被卸载。
- 重设 umask:将 umask 设置为 0,以便守护进程创建的任何文件或目录具有合适的权限。这样可以避免权限问题。
- 关闭文件描述符:关闭从父进程继承的所有打开的文件描述符。通常,需要循环遍历所有可能的文件描述符,从 0 开始,一直到系统定义的最大文件描述符。
- 重定向标准文件描述符:使用 open() 系统调用打开 /dev/null。然后使用 dup2() 系统调用将标准输入、标准输出和标准错误重定向到刚打开的 /dev/null。这样可以避免输出混乱和不必要的资源占用。
- 设置信号处理:使用 sigaction() 或 signal() 函数设置适当的信号处理程序,以便守护进程能够优雅地处理系统发送的信号。例如,确保在收到 SIGTERM 信号时守护进程可以正常终止。
- 启动核心服务:编写守护进程的核心功能,处理任务并在需要时与其他系统组件交互。这可能包括监听套接字、执行周期性任务或监视文件系统更改。
- 使用锁文件或 PID 文件:使用 open() 和 write() 系统调用创建一个锁文件或 PID 文件,将守护进程的进程 ID 写入其中。这有助于避免同一守护进程的多个实例同时运行,并允许其他进程监视或管理守护进程。
- 使用系统日志:使用 syslog() 函数将重要信息、错误或警告记录到系统日志,以便管理员能够监视守护进程的状态和活动。这通常包括配置日志优先级、打开日志连接并在创建守护进程时,确保将关键信息、错误或警告记录到系统日志中非常重要。
注:
(1)PID,PGID,SID三者一致,父进程为1号进程,且脱离终端,可知某进程是否为守护进程
(2)ps axj显示结果中的TTY栏,”?”表示脱离控制终端。
举个栗子:
以守护进程的方式,每隔1秒,向指定文件中写入指定格式的当前系统时间:
1 | // mydaemon.c |
注:运行时需要root权限,杀死该进程:sudo killall mydaemon。
通过 ps axj 指令查看mydaemon进程为守护进程,通过 sudo tail -f /var/log/mydaemon.log 动态查看文件内容。
系统日志
每个应用程序都有必要写系统日志,但不是每一个程序都有权限去写,所以都把内容提交给syslogd服务,由它统一去写。权限分割。
SYSLOG(3)
NAME
closelog, openlog, syslog - send messages to the system logger
SYNOPSIS
#include <syslog.h>
void openlog(const char *ident, int option, int facility);
void syslog(int priority, const char *format, …);
void closelog(void);
DESCRIPTION
openlog()
openlog() opens a connection to the system logger for a program.
The string pointed to by ident is prepended to every message, and is typically set to the program name. If ident is NULL, the program name is used. (POSIX.1-2008 does not specify the behavior when ident is NULL.)
The option argument specifies flags which control the operation of openlog() and subsequent calls to syslog(). The facility argument establishes a default to be used if none is specified in subsequent calls to syslog(). The values that may be specified for option and facility are described below.
The use of openlog() is optional; it will automatically be called by syslog() if necessary, in which case ident will default to NULL.
syslog()
syslog() generates a log message, which will be distributed by syslogd(8).
The priority argument is formed by ORing together a facility value and a level value (described below). If no facility value is ORed into priority, then the default value set by openlog() is used, or, if there was no preceding openlog() call, a default of LOG_USER is employed.
The remaining arguments are a format, as in printf(3), and any arguments required by the format, except that the two-character sequence %m will be replaced by the error message string strerror(errno). The format string need not include a terminating newline character.
closelog()
closelog() closes the file descriptor being used to write to the system logger. The use of closelog() is optional.
openlog(3)
openlog() 函数用于打开与系统日志守护进程的连接。它允许设置日志选项、指定消息来源标识符和定义消息设施。函数原型如下:
1 | void openlog(const char *ident, int option, int facility); |
参数说明:
ident:一个字符串,用作消息来源的标识符。此字符串将添加到每条日志消息的开头。option:一个位掩码,用于设置日志选项。例如,LOG_CONS(如果消息无法发送到系统日志,则将其写入控制台)、LOG_PID(在每条消息中包含调用进程的进程 ID)、LOG_NDELAY(立即打开与系统日志的连接,而不是在写入第一条消息时)等。facility:一个整数,表示消息的来源类型。例如,LOG_USER(用户级消息)、LOG_LOCAL0(本地使用的设施 0)、LOG_DAEMON(系统守护进程)等。
示例:openlog(“my_daemon”, LOG_PID | LOG_CONS, LOG_DAEMON);
syslog(3)
syslog() 函数用于向系统日志写入日志消息。它接受一个整数优先级和一个格式化字符串作为参数,以及与格式化字符串中的格式说明符对应的可变参数列表。函数原型如下:
1 | void syslog(int priority, const char *format, ...); |
参数说明:
priority:消息的优先级,由一个或多个日志级别(例如,LOG_ERR、LOG_WARNING)和一个日志设施(例如,LOG_USER、LOG_DAEMON)组成。日志级别和日志设施可以使用按位或运算符(|)组合。format:一个格式化字符串,类似于 printf() 函数使用的字符串。它可以包含格式说明符(例如,%s、%d),以及用于描述消息内容的文本。...:可变参数列表,与格式字符串中的格式说明符相对应。
示例:syslog(LOG_ERR | LOG_USER, “An error occurred: %s”, error_message);
closelog(3)
closelog() 函数用于关闭与系统日志守护进程的连接。在程序结束时调用此函数是一种良好的做法,尽管在程序退出时,资源会自动释放。
举个栗子:
1 | // syslog.c |
在运行此示例程序后,可以在系统日志中找到相应的日志记录。在许多 Linux 发行版中,这些记录可以在 /var/log/syslog 或 /var/log/messages 文件中找到。
1 | kernel@Ubuntu22:/var/log$ tail syslog |