前言
玩pwn的时候,有时要用到got表覆写技术,本文在于分享对GOT表覆写技术的理解,铺垫性的基础知识较多,目的在于让初学者知其然,还要知其所以然!
ELF文件生成过程
1 | //hello.c |
注:gcc命令实际上是具体程序(如ccp、cc1、as等)的包装命令,用户通过gcc命令来使用具体的预处理程序ccp、编译程序cc1和汇编程序as等。
预处理过程
主要处理源文件中以“#”开头的预编译指令,经过预编译处理后,得到的是预处理文件(如,hello.i) ,它还是一个可读的文本文件 。
1 | $gcc –E hello.c –o hello.i |
编译过程
将预处理后得到的预处理文件(如 hello.i)进行词法分析、语法分析、语义分析、优化后,生成汇编代码文件。经过编译后,得到的汇编代码文件(如 hello.s)还是可读的文本文件,CPU无法理解和执行它。
1 | $gcc –S hello.i –o hello.s //或者$gcc –S hello.c –o hello.s |
汇编过程
汇编程序(汇编器)用来将汇编语言源程序转换为机器指令序列(机器语言程序)。汇编结果是一个可重定位目标文件(如 hello.o),其中包含的是不可读的二进制代码,必须用相应的工具软件来查看其内容。
1 | $gcc –c hello.s –o hello.o //或者$gcc –c hello.c –o hello.o |
预处理、编译和汇编三个过程针对一个模块(一个*.c文件)进行处理,得到对应的一个可重定位目标文件(一个*.o文件)。
链接过程
将多个可重定位目标文件合并以生成可执行目标文件
1 | 链接过程指令较复杂,此处不详细说明,具体可以参考《程序员的自我修养》第二章 |
目标文件格式概述
三类目标文件
1、可重定位目标文件 (Relocatable File; 后缀名为“.o”)
1 | 1) Linux下的.o(Windows下的.obj); |
2、可执行目标文件(Executable File;一般没有后缀名)
1 | 1) 包含的代码和数据可以被直接复制到内存并被执行 |
3、共享的目标文件 (Shared Object File;后缀名为“.so”)
1 | 1) 链接器可使用.so文件跟其他.o文件和.so文件链接以生成新的.o文件 |
标准的几种目标文件格式
DOS操作系统(最简单) :COM格式,文件中仅包含代码和数据,且被加载到固定位置;System V UNIX早期版本:COFF格式,文件中不仅包含代码和数据,还包含重定位信息、调试信息、符号表等其他信息,由一组严格定义的数据结构序列组成;Windows: PE格式(COFF的变种),称为可移植可执行(Portable Executable,简称PE);
4)Linux等类UNIX:ELF格式(COFF的变种),称为可执行可链接(Executable and Linkable Format,简称ELF);
两种视图
链接视图(被链接):可重定位目标文件(Relocatable object files)

1 | 1) 可被链接(合并)生成可执行文件或共享目标文件 |
执行视图(被执行):可执行目标文件(Executable object files)

1 | 1) 定义的所有变量和函数已有确定地址(虚拟地址空间中的地址) |
ELF可重定位目标文件
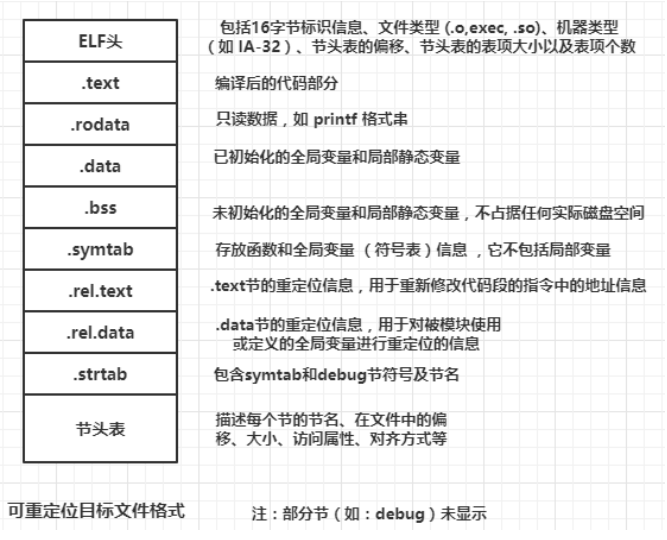
.bss 节
1 | C语言规定: 未初始化的全局变量和局部静态变量的默认初始值为0 |
ELF可执行目标文件
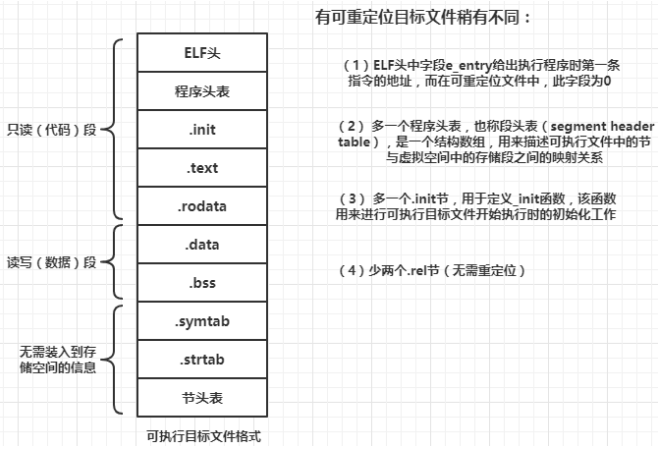
符号及符号表
链接操作的步骤
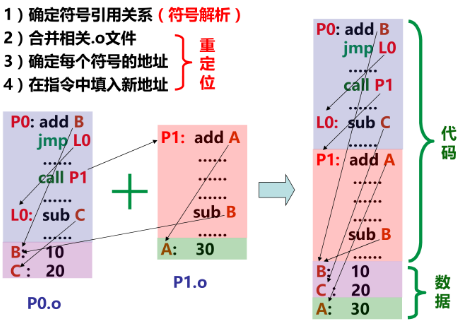
Step 1. 符号解析(Symbol resolution)
1 | 1) 确定程序中有定义和引用的符号 (包括变量和函数等) |
Step 2. 重定位
1 | 1) 合并相同的节:将集合E中所有目标模块中相同的节分别合并为一个新节; |
1 | //main.c |
链接符号的类型
每个可重定位目标模块m都有一个符号表,它包含了在m中定义和引用的符号。有三种链接器符号:
1 | (1) Global symbols(模块内部定义的全局符号) |
目标文件中的符号表
1 | .symtab 节记录符号表信息,是一个结构数组,函数名在text节中,变量名在data节或bss节中 |
静态链接和符号解析
静态链接对象
多个可重定位目标模块 + 静态库(标准库、自定义库)
(.o文件) (.a文件,其中包含多个.o模块)
静态库 (.a archive files)
1 | 1) 将所有相关的目标模块(.o)打包为一个单独的库文件(.a),称为静态库文件 ,也称存档文件 (archive) |
自定义一个静态库文件
1 | //program1.c |
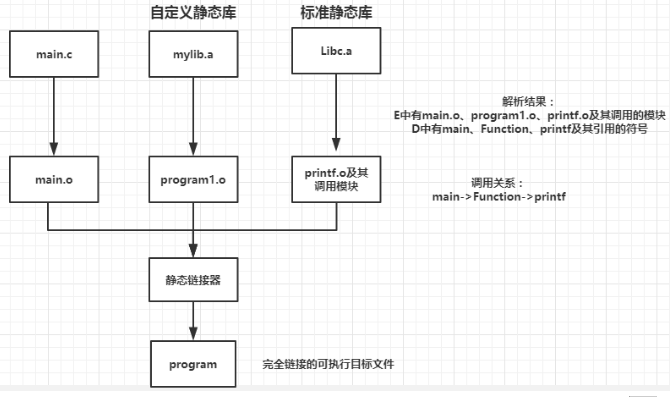
链接器中符号解析的全过程
三个重要集合:E 将要被合并以组成可执行文件的所有目标文件集合U 当前所有未解析的引用符号的集合D 当前所有定义符号的集合
开始E、U、D为空,首先扫描main.o,把它加入E,同时把Function加入U,main加入D。接着扫描到mylib.a,将U中所有符号(本例中为Function)与mylib.a中所有目标模块(program1.o和program2.o)依次匹配,发现在program1.o中定义了Function,故program1.o加入E,Function从U转移到D。在program1.o中发现还有未解析符号printf,将其加到U。不断在mylib.a的各模块上进行迭代以匹配U中的符号,直到U、D都不再变化。此时U中只有一个未解析符号printf,而D中有main和Function。因为模块program2.o没有被加入E中,因而它被丢弃。接着,扫描默认的库文件libc.a,发现其目标模块printf.o定义了printf,于是printf也从U移到D,并将printf.o加入E,同时把它定义的所有符号加入D,而所有未解析符号加入U。处理完libc.a时,U一定是空的。
注:被链接模块应按调用顺序指定!
若命令为:
1 | $ gcc -m32–static –o myproc ./mylib.a main.o |
首先,扫描mylib,因是静态库,应根据其中是否存在U中未解析符号对应的定义符号来确定哪个.o被加入E。因为开始U为空,故其中两个.o模块都不被加入E中而被丢弃。然后,扫描main.o,将Function加入U,直到最后它都不能被解析,因此,出现链接错误,因为它只能用mylib.a中符号来解析,而mylib中两个.o模块都已被丢弃!
可执行文件的加载
通过调用execve系统调用函数来调用加载器:
1 | 1) 加载器(loader)根据可执行文件的程序(段)头表中的信息,将可执行文件的代码和数据从磁盘“拷贝”到存储器中 |
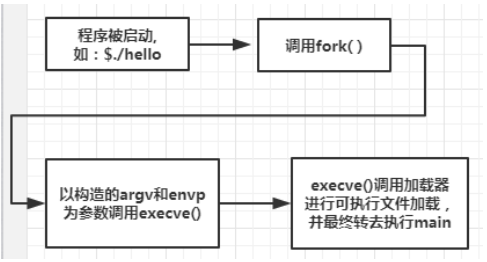
execve()函数的用法如下:
1 | int execve(char *filename, char *argv[], *envp[]); |
filename是加载并运行的可执行文件名(如./hello),可带参数列表argv和环境变量列表envp。若错误(如找不到指定文件filename),则返回-1,并将控制权交给调用程序; 若函数执行成功,则不返回,最终将控制权传递到可执行目标中的主函数main。
主函数main()的原型形式如下:
1 | int main(int argc, char **argv, char **envp); //或者 |
argc指定参数个数,参数列表中第一个总是命令名(可执行文件名)
hello程序的加载和运行过程
1 | Step1:在shell命令行提示符后输入命令:$./hello; |
共享库和动态链接【划重点】
静态库有一些缺点
1 | 1) 库函数(如printf)被包含在每个运行进程的代码段中,对于并发运行上百个进程的系统,造成极大的主存资源浪费 |
解决方案: Shared Libraries (共享库)
1 | 1) 是一个目标文件,包含有代码和数据 |
自定义一个动态共享库文件
1 | //program3.c |
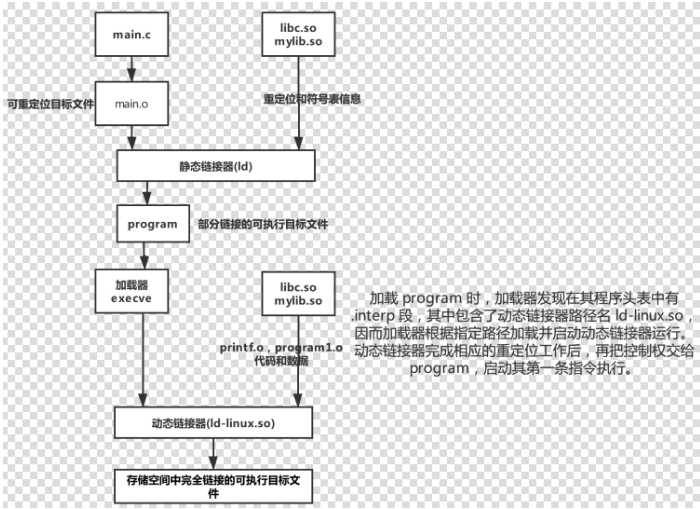
地址无关代码【划重点】
• 动态链接用到一个重要概念:
我们希望程序模块中共享的指令部分在装载时不需要因为装载地址的改变而改变,所以实现的基本想法就是把指令中那些需要被修改的部分分离出来,跟数据部分放在一起,这样指令部分就可以保持不变,而数据部分可以在每个进程中拥有一个副本。这种方案就叫做**地址无关代码(Position-Independent Code,PIC)**。
1 | GCC选项-fPIC指示生成PIC代码 |
• 共享库代码是一种PIC
1 | 共享库代码的位置可以是不确定的 |
• 所有引用情况
1 | (1) 模块内的数据访问。如模块内的全局变量和静态变量 |
要实现动态链接,必须生成PIC代码,要生成PIC代码,主要解决第3和第4这两个问题
1 | 源代码: |
(1)模块内的函数调用或跳转
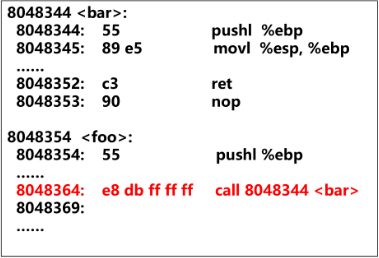
调用或跳转源与目的地都在同一个模块,相对位置固定,只要用相对偏移寻址即可。call的目标地址为:0x8048369 + 0xffffffdb(-0x25) = 0x8048344
注:
1 | 8048364: e8 db ff ff ff call 8048344 <bar> |
该指令是一条近址相对位移调用指令
(2)模块内的数据引用

注:任何一条指令与它需要访问的模块内部数据之间的相对位置是固定的,那么只要相对于当前指令加上固定的偏移量就可以访问模块内部的数据了。
变量a与引用a的指令之间的距离为常数,调用__get_pc后,call指令的返回地址被置ECX。若模块被加载到0x9000000,则a的访问地址为:0x9000000+0x34c+0x118c(指令与.data间距离)+0x28(a在.data节中偏移)
(3)模块间的数据访问ELF解决模块间的数据访问目标地址的做法是在数据段里面建立一个指向这些变量的指针数组,也称为全局偏移表(Global Offset Table,Got),当代码需要引用该全局变量时,可通过GOT中相对应的项间接引用。
模块在编译时可以确定GOT相对于当前指令的偏移,然后根据变量地址在GOT中的偏移就可得到变量的地址。比如,当指令要访问变量b时,程序会先找到GOT,然后根据GOT中变量所对应的项找到变量的目标地址。
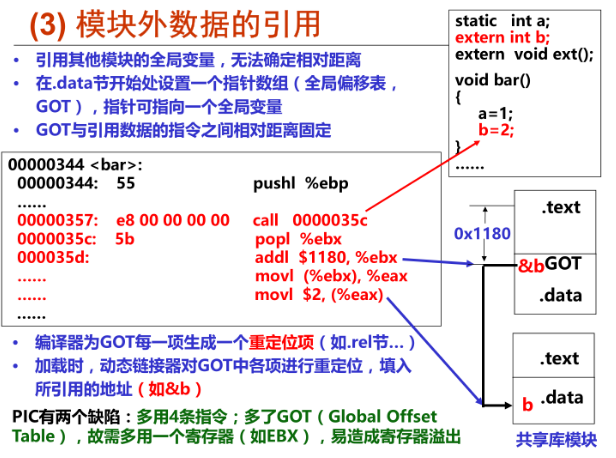
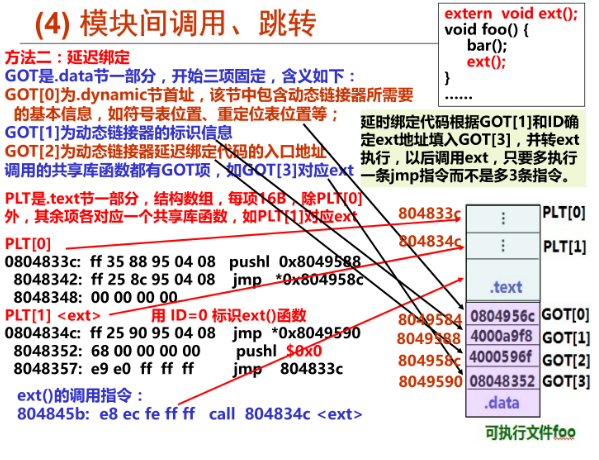
(4)模块间的调用、跳转
同理,我们可以使用类似于模块间的数据访问的方式,在GOT中加一个项(指针),用于指向目标函数的首地址(如&ext),但是也要多用三条指令并额外多用一个寄存器(如EBX)。因此,可用“延迟绑定(lazy binding)”技术来优化动态链接性能:当函数第一次被用到时才进行绑定(符号查找、重定位等),这样可以大大加快程序启动速度。ELF使用PLT(Procedure linkage Table, 过程链接表)的方法来实现。通常我们调用某个外部模块的函数时,应该是通过GOT中相应的项进行间接跳转。而PLT为了实现延迟绑定,在这个过程中有增加了一层间接跳转。调用函数并不直接通过GOT跳转,而是通过一个叫作PLT项的结构来进行跳转。每个外部函数在PLT中都有一个相应的项,比如bar()在PLT中的项的地址我们称为bar@plt。其中bar@plt的实现如下:
1 | bar@plt: |
第一条指令是通过一条GOT间接跳转的指令。bar@GOT表示GOT中保存的bar()这个函数相应的项。链接器在初始化阶段没有将bar()的地址填入到该项中,而是将上面代码中第二条指令“push n”的地址填入到bar@GOT中。显然,第一条指令的效果是跳转到第二条指令,第二条指令将一个数字n压入堆栈中,该数字为bar这个符号引用在重定位表“.rel.plt”中的下标。接着将模块的ID压入堆栈中,然后调用_dl_runtime_resolve函数来完成符号解析和重定位工作。_dl_runtime_resolve在进行一系列工作以后将bar()的真正地址填入到bar@GOT中。再次调用bar@plt时,第一条jump指令能跳转到真正的bar()函数中,bar()函数返回的时候会根据堆栈里保存的EIP直接返回到调用者,而不会在继续执行bar@plt中第二条指令开始的那段代码。ELF将GOT拆分为两个表叫做“.got”和“.got.plt”:
1 | 1) .got 用来保存全局变量引用的地址; |
注:Linux下,ELF可执行文件虚拟地址空间默认从地址0x08048000开始分配
实践部分
理解了何为GOT表和PLT之后,我们再通过pwnable.kr中的题目passcode来介绍一下GOT表覆盖技术:
1 | Mommy told me to make a passcode based login system. |
解题思路:
由于welcome()和login()函数调用栈的EBP相同,通过gdb调试后可以发现
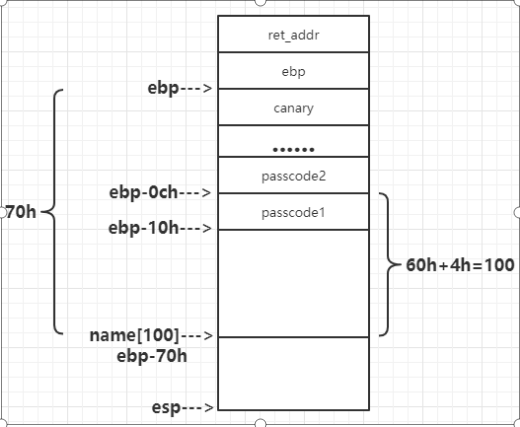
输入的变量没有用取地址符号&,导致读入数据的时候,scanf会把这个变量中的值当成存储地址来存放数据,name值的最后4个字节是passcode1值,所以可以通过将passcode1的值改为fflush()的地址,scanf()之后会调用fflush()函数,覆盖fflush()在GOT表中的内容,把system(“/bin/cat flag”)对应汇编代码地址写入fflush()中,当这个函数被调用时,就会直接执行system(“/bin/cat flag”)。
通过objdump -R passcode命令查看GOT表可以发现fflush()位于0x0804a004处,即将0x80485e3(调用system的地址)覆写位于0x0804a004的fflush()函数的GOT表。
1 | //exp.py |
参考资料
《程序员的自我修养》
《计算机系统基础(一):程序的表示、转换与链接》
注:本文首发于安全客